命令 查看版本
查看oracle数据库(database)的版本命令_花果山-CSDN博客
1 2 3 select * from v$version ;select version from v$instance ;Select version FROM Product_component_version Where SUBSTR (PRODUCT,1 ,6 )='Oracle' ;
批量插入 1 2 3 4 5 6 7 8 INSERT INTO USER ( ID , USERNAME, PASSWORD , CREATE_DATE, DEL_FLAG ) SELECT SEQ_USER.nextval, t.* FROM ( SELECT 'zhangsan' USERNAME, 'zxode23' PASSWORD , SYSDATE CREATE_DATE, 0 DEL_FLAG FROM dual UNION ALL SELECT 'lisi' USERNAME, '9fhd2fd' PASSWORD , SYSDATE CREATE_DATE, 0 DEL_FLAG FROM dual ) t
MyBatis 批量插入,使用序列做自增ID
1 2 3 4 5 6 7 8 <insert id ="insertList" > INSERT INTO USER ( ID, USERNAME, PASSWORD, CREATE_DATE, DEL_FLAG ) SELECT SEQ_USER.nextval, t.* FROM <foreach collection ="list" item ="item" open ="(" separator ="UNION ALL" close =")" > SELECT #{item.USERNAME} USERNAME, #{item.PASSWORD} PASSWORD, SYSDATE CREATE_DATE, 0 DEL_FLAG FROM dual </foreach > t </insert >
union all:不去重
union:去重
ORDER BY 缺省值 NULL
数字 ORDER BY 后面跟数字,代表排序字段为查询结果字段中的第几个。
例如
1 SELECT ID , NAME , EMAIL, PHONE FROM SYS_USER ORDER BY 1
等价于
1 SELECT ID , NAME , EMAIL, PHONE FROM SYS_USER ORDER BY ID
EXISTS
EXISTS Condition | Oracle
An EXISTS condition tests for existence of rows in a subquery.
一般情况下公司数据库不会加外健来关联两张表,查询时为了避免数据不存在会使用 EXISTS 进行过滤。
1 2 3 4 5 6 7 8 9 10 11 12 13 SELECT d.department_id FROM departments d WHERE EXISTS ( SELECT * FROM employees e WHERE d.department_id = e.department_id )
GROUP BY VS PARTITION BY
Oracle 对于 GROUP BY 是严格的,oracle 中规定,使用 group by 时,select 后面所有不是聚合函数的字段,都必须出现在 group by 后面,否则会报错:“ORA-00979: not a GROUP BY expression”。而 MySQL 则不同,如果 SELECT 出来的字段在 GROUP BY 后面没有出现,那么会随机取出一个值。
partition by and group by | Oracle
Totally different things.
GROUP BY is about aggregation. Take ‘n’ rows and reduce the number of rows (by summing, or max, or min etc)..But we are consolidating some data.
PARTITION BY is about carving up data into chunks. Take ‘n’ rows, apply some rule to split the rows into buckets…but will still have ‘n’ rows.
GROUP BY 是关于聚合函数的,PARTITION BY 是敢于分析函数的。
对于 n 行数据,GROUP BY 返回的肯定小于等于 n 行,而 PARTITION BY 会返回 n 行。
eg:求各部门员工工资总和
1 2 3 4 5 6 7 8 SELECT deptno 部门编号,SUM (sal) 部门工资总和 FROM emp GROUP BY deptno;| 部门编号 | 部门工资总和 | | 30 | 10900 | | 20 | 10575 | | 10 | 9250 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 SELECT deptno 部门编号,SUM (SAL) OVER (partition by sal) 部门工资总和 FROM emp;| 部门编号 | 部门工资总和 | | 30 | 1450 | | 30 | 1500 | | 30 | 3200 | | 20 | 3200 | | 30 | 3500 | | 30 | 3500 | | 10 | 1800 | | 10 | 2450 | | 30 | 2850 | | 20 | 2975 | | 20 | 6000 | | 20 | 6000 | | 10 | 5000 | SELECT deptno 部门编号 ,ename 员工姓名, sal 员工工资, SUM (sal) OVER (PARTITION BY deptno ORDER BY sal) 所在部门工资总和 FROM emp;| 部门编号 | 员工姓名 | 员工工资 | 所在部门工资总和 | | 10 | MILLER | 1800 | 1800 | | 10 | CLARK | 2450 | 4250 | | 10 | KING | 5000 | 9250 | | 20 | ADAMS | 1600 | 1600 | | 20 | JONES | 2975 | 4575 | | 20 | SCOTT | 3000 | 10575 | | 20 | FORD | 3000 | 10575 | | 30 | JAMES | 1450 | 1450 | | 30 | TURNER | 1500 | 2950 | | 30 | ALLEN | 1600 | 4550 | | 30 | WARD | 1750 | 8050 | | 30 | MARTIN | 1750 | 8050 | | 30 | BLAKE | 2850 | 10900 |
递归查询 语法:
1 SELECT ... FROM tablename WHERE ... START WITH ... CONNECT BY PRIOR ...
eg:
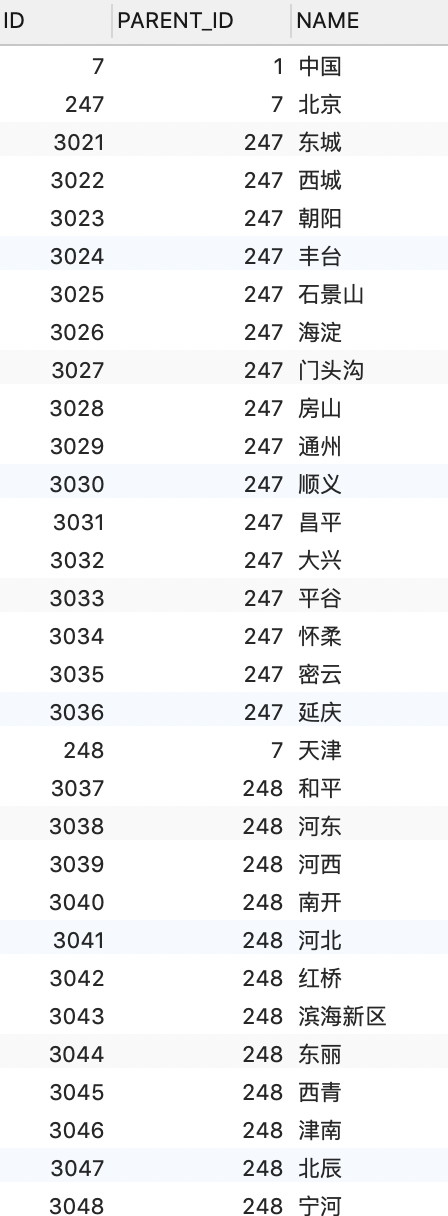
地址表 GLOBAL_LOCATION
查询北京所有的子孙节点
1 SELECT ID , PARENT_ID, NAME FROM GLOBAL_LOCATION START WITH PARENT_ID = 247 CONNECT BY PRIOR ID = PARENT_ID
查询海淀所有的祖先节点
1 SELECT ID , PARENT_ID, NAME FROM GLOBAL_LOCATION START WITH ID = 3026 CONNECT BY PRIOR PARENT_ID = ID
执行计划 查看执行计划的方法
Explain Plan For SQL
不实际执行 SQL 语句,生成的计划未必是真实执行的计划
必须要有 plan_table 表
SQLPLUS AUTOTRACE
除 set autotrace traceably explain 外均实际执行 SQL,但仍未必是真实计划
必须要有 plan_table
它只是简单的在后台执行 “explain plan” 并且调用 “dbms_xplan.display”;
SQL TRACE
需要启用 10046 或者 SQL_TRACE
一般用 tkprof 看的更清楚些,当然 10046 里本身也有执行计划信息
V$SQL 和 V$SQL_PLAN
可以查询到多个子游标的计划信息了,但是看起来比较费劲
Enterprise Manager
可以图形化显示执行计划,但并非所有环境有 EM 可用
其他第三方工具
注意 PL/SQL developer 之类工具 F5 看到的执行计划未必是真实的。
1 2 3 4 5 6 7 8 SELECT lpad ('-' , 5 * ( LEVEL - 1 )) || operation operation, options, object_name, cost , position FROM plan_table START WITH id = 0 CONNECT BY PRIOR id = parent_id;
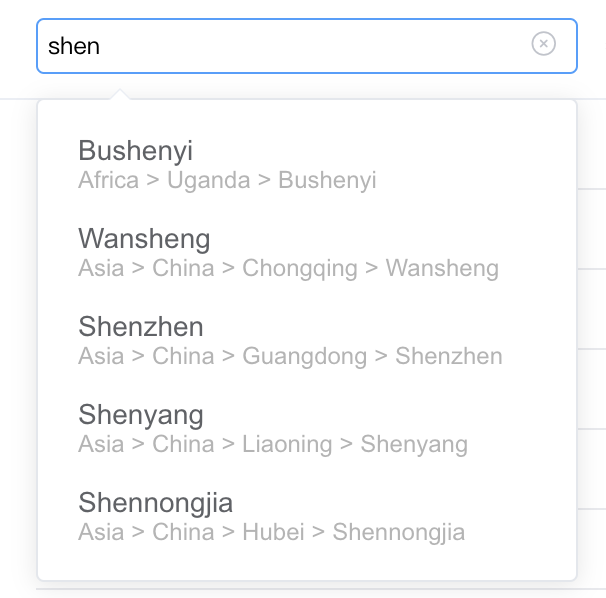
Comprehensive examples in work 地址树远程搜索 需求说明:input 框中输入地址,远程搜索出匹配节点,由于同名地址到存在,要求将完整地址一同显示。
表结构:
1 2 3 4 5 6 CREATE TABLE "SKYSTAR" ."GLOBAL_LOCATION_copy1" ( "ID" NUMBER (20 ) VISIBLE NOT NULL , "PARENT_ID" NUMBER (20 ) VISIBLE , "PATH" VARCHAR2 (100 BYTE ) VISIBLE , "ENGLISH_NAME" VARCHAR2 (255 BYTE ) VISIBLE )
样例数据:
1 INSERT INTO "GLOBAL_LOCATION" ("ID" , "PARENT_ID" , "PATH" , "ENGLISH_NAME" ) VALUES ('250' , '7' , ',1,7,250,' , 'Shanxi' );
根据输入查找节点
1 SELECT ID , ENGLISH_NAME, PATH FROM GLOBAL_LOCATION WHERE UPPER (ENGLISH_NAME) LIKE '%' || UPPER (
去掉 PATH 前后的 ,
1 SELECT SUBSTR ( ',1,7,250,' , 2 , LENGTH ( ',1,7,250,' ) - 2 ) FROM dual
将去掉前后 , 的路径 PATH 按 , 分割得到祖先 ID
1 2 3 4 SELECT REGEXP_SUBSTR( '1,7,250' , '[^,]+' , 1 , ROWNUM ) FROM dual CONNECT BY ROWNUM <= LENGTH ( '1,7,250' ) - LENGTH (REGEXP_REPLACE( '1,7,250' , ',' , '' )) + 1
查找所有祖先节点,并使用 > 连接
1 2 3 4 SELECT LISTAGG ( ENGLISH_NAME, ' > ' ) WITHIN GROUP ( ORDER BY ID ) address FROM ( SELECT ID , ENGLISH_NAME FROM GLOBAL_LOCATION WHERE ID IN ( 1 , 7 , 250 ) )
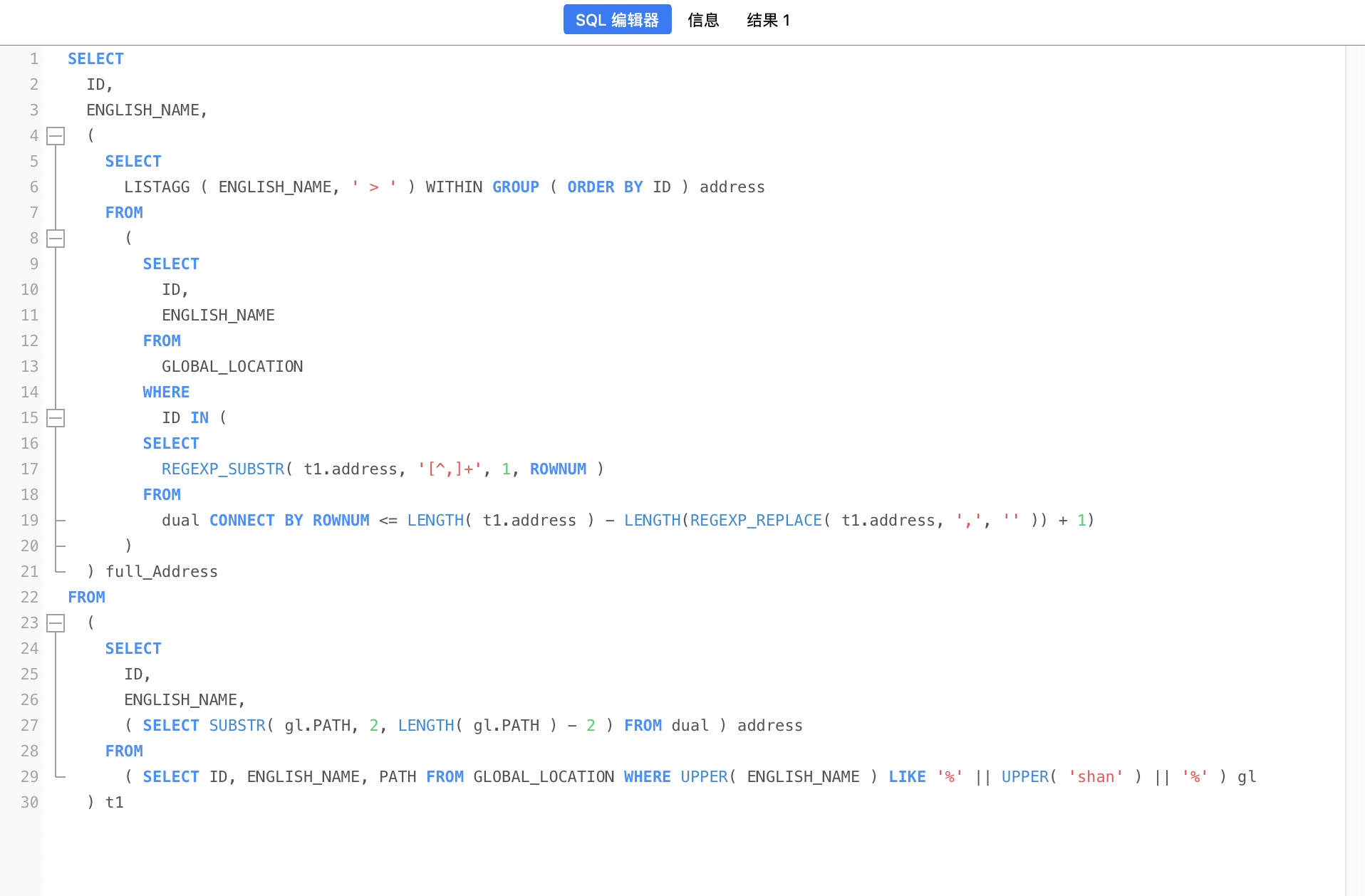
汇总后的 SQL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 SELECT ID , ENGLISH_NAME, ( SELECT LISTAGG ( ENGLISH_NAME, ' > ' ) WITHIN GROUP ( ORDER BY ID ) ADDRESS FROM ( SELECT ID , ENGLISH_NAME FROM GLOBAL_LOCATION WHERE ID IN ( SELECT REGEXP_SUBSTR( t1.ADDRESS, '[^,]+' , 1 , ROWNUM ) FROM dual CONNECT BY ROWNUM <= LENGTH ( t1.address ) - LENGTH (REGEXP_REPLACE( t1.ADDRESS, ',' , '' )) + 1 ) ) ) FULL_ADDRESS FROM ( SELECT ID , ENGLISH_NAME, ( SELECT SUBSTR ( gl.PATH, 2 , LENGTH ( gl.PATH ) - 2 ) FROM dual ) ADDRESS FROM ( SELECT ID , ENGLISH_NAME, PATH FROM GLOBAL_LOCATION WHERE UPPER ( ENGLISH_NAME ) LIKE '%' || UPPER ( 'shan' ) || '%' ) gl ) t1
触发器(TRIGGER)
Top n
Top-N Queries
1 SELECT * FROM USERS WHERE ROWNUM < 10 ORDER BY ID DESC
分组 Top n
oracle中分组排序取TOP n_weixin_30692143的博客-CSDN …
1 2 3 4 5 6 SELECT * FROM ( SELECT u.ID, u.NAME, row_number () over ( partition BY GROUP_ID ORDER BY ID ) rn FROM USERS u ) WHERE rn < 5
链接查询 vs 子查询 ERROR ORA-03113
Oracle错误——ORA-03113:通信通道的文件结尾 解决办法
问题描述 Oracle 中使用 COUNT(DISTINCT xxx) 时出现:
1 ORA-03113:end -of -file on communication channel
而且只有在原始表中执行会报这个错,将原始表复制后再执行又不报错,或者把 DISTINCT 去掉再执行也不报错。
SQL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 SELECT t.address_cityTown AS ID , gl.PATH, COUNT ( DISTINCT t.id ) AS collectedQTY FROM ( SELECT cr.id, jt.* FROM ( SELECT * FROM CUSTOMER_RAW WHERE DEL_FLAG = 0 ) cr, JSON_TABLE ( DATA , '$.generalInfo.address[*]' COLUMNS ( row_number FOR ORDINALITY , address_cityTown NUMBER ( 20 ) PATH '$.cityTown' )) AS jt ) t LEFT JOIN GLOBAL_LOCATION gl ON t.address_cityTown = gl.ID GROUP BY t.address_cityTown, gl.PATH
TABLE
CUSTOMER_RAW.sql
ORA-04098
Oracle触发器,解决ORA-04098: 触发器 ‘USER.DECTUSERTEST_TRI’ 无效且未通过重新验证
问题描述 创建了一个触发器,在执行触发事件的 SQL 时报错:
1 ORA-04098: trigger 'SKYSTAR.COUNT_COLLECTED_QTY' is invalid and failed re-validation
触发器 1 2 3 4 5 6 7 CREATE OR REPLACE TRIGGER Count_Collected_Qty AFTER INSERT ON CUSTOMER_RAW_TESTFOR each ROW BEGIN UPDATE GLOBAL_LOCATION_TEST SET COLLECTED_QTY = COLLECTED_QTY + 1 END ;
触发 SQL 1 2 INSERT INTO "CUSTOMER_RAW_TEST" ("ID" , "DATA" , "SOURCE_TYPE_ID" , "STATUS" , "CREATE_BY" , "CREATE_DATE" , "UPDATE_BY" , "UPDATE_DATE" , "DEL_FLAG" , "GOOGLE_FLAG" , "GOOGLE_ADDRESS" , "PROCESS_FLAG" ) VALUES ('5' , '{"generalInfo":{"address":[{"country":5100,"countryName":"Test Country A","state":5110,"stateName":"Test State AA","cityTown":5111,"cityTownName":"Test City AAA"}]}}' , '1' , '213' , '1435' , TO_DATE ('2019-09-16 15:36:37' , 'SYYYY-MM-DD HH24:MI:SS' ), '1435' , TO_DATE ('2019-09-16 15:36:37' , 'SYYYY-MM-DD HH24:MI:SS' ), '0' , NULL , NULL , NULL );
TABLE GLOBAL_LOCATION_TEST.sql
CUSTOMER_RAW_TEST.sql
原因 触发操作中的 SQL 语句没有加 ;
ORA-00933 问题描述 union/union all 连接的语句中只能有一个 order by (不包含子查询中的)否则会报 SQL command not properly ended。
1 2 3 4 5 6 7 8 9 10 11 12 13 SELECT p.productId, p.productTitle, p.price, p.productQty, i.imagesId, i.imagesType, i.imagesPathFROM PRODUCTS pLEFT JOIN PRODUCTIMAGES pi ON p.PRODUCTID = pi.PRODUCTIDLEFT JOIN IMAGES i ON pi.IMAGESID = i.IMAGESIDWHERE p.PRODUCTID = 123 ORDER BY i.imagesType, i.imagesId UNION ALL SELECT p.productId, p.productTitle, p.price, p.productQty, i.imagesId, i.imagesTitle, i.imagesType, i.imagesPathFROM PRODUCTS pLEFT JOIN PRODUCTIMAGES pi ON p.PRODUCTID = pi.PRODUCTIDLEFT JOIN IMAGES i ON pi.IMAGESID = i.IMAGESIDWHERE p.PRODUCTID = 456 ORDER BY i.imagesType, i.imagesId
解决方法 将 order by 放在子查询中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 SELECT p.productId, p.productTitle, p.price, p.productQty, i.imagesId, i.imagesType, i.imagesPath FROM PRODUCTS p LEFT JOIN ( SELECT pi.PRODUCTID, img.IMAGESID, img.TYPE, img.imagesTitle, img.imagesType, img.imagesPath FROM PRODUCTIMAGES pi LEFT JOIN IMAGES img ON pi.IMAGESID = img.IMAGESID ORDER BY img.TYPE, img.IMAGESID ) i ON p.PRODUCTID = i.PRODUCTID WHERE p.PRODUCTID = 123 UNION ALL SELECT p.productId, p.productTitle, p.price, p.productQty, i.imagesId, i.imagesTitle, i.imagesType, i.imagesPath FROM PRODUCTS p LEFT JOIN ( SELECT pi.PRODUCTID, img.IMAGESID, img.TYPE, img.imagesTitle, img.imagesType, img.imagesPath FROM PRODUCTIMAGES pi LEFT JOIN IMAGES img ON pi.IMAGESID = img.IMAGESID ORDER BY img.TYPE, img.IMAGESID ) i ON p.PRODUCTID = i.PRODUCTID WHERE p.PRODUCTID = 456