
第一部分 走近Java
第1章 走近Java
世界上并没有完美的程序,但我们并不因此而沮丧,因为写程序本来就是一个不断追求完美的过程
1.1 概述
Java 的优点:
结构严谨
因为 Java 只支持面向对象这一种编程范式
面向对象
在面向对象编程中,程序员认为程序是一系列相互作用的对象
摆脱了硬件平台的束缚,实现了“一次编写,到处运行”的理想
提供了一种相对安全的内存管理和访问机制,避免了绝大部分内存泄漏和指针越界问题
实现了热点代码检测和运行时编译及优化,使得应用能随着运行时间的增长而获得更高的性能
有一套完善的应用程序接口,还有无数来自商业机构和开源社区的第三方类库来帮助用户实现各种各样的功能
1.2 Java技术体系
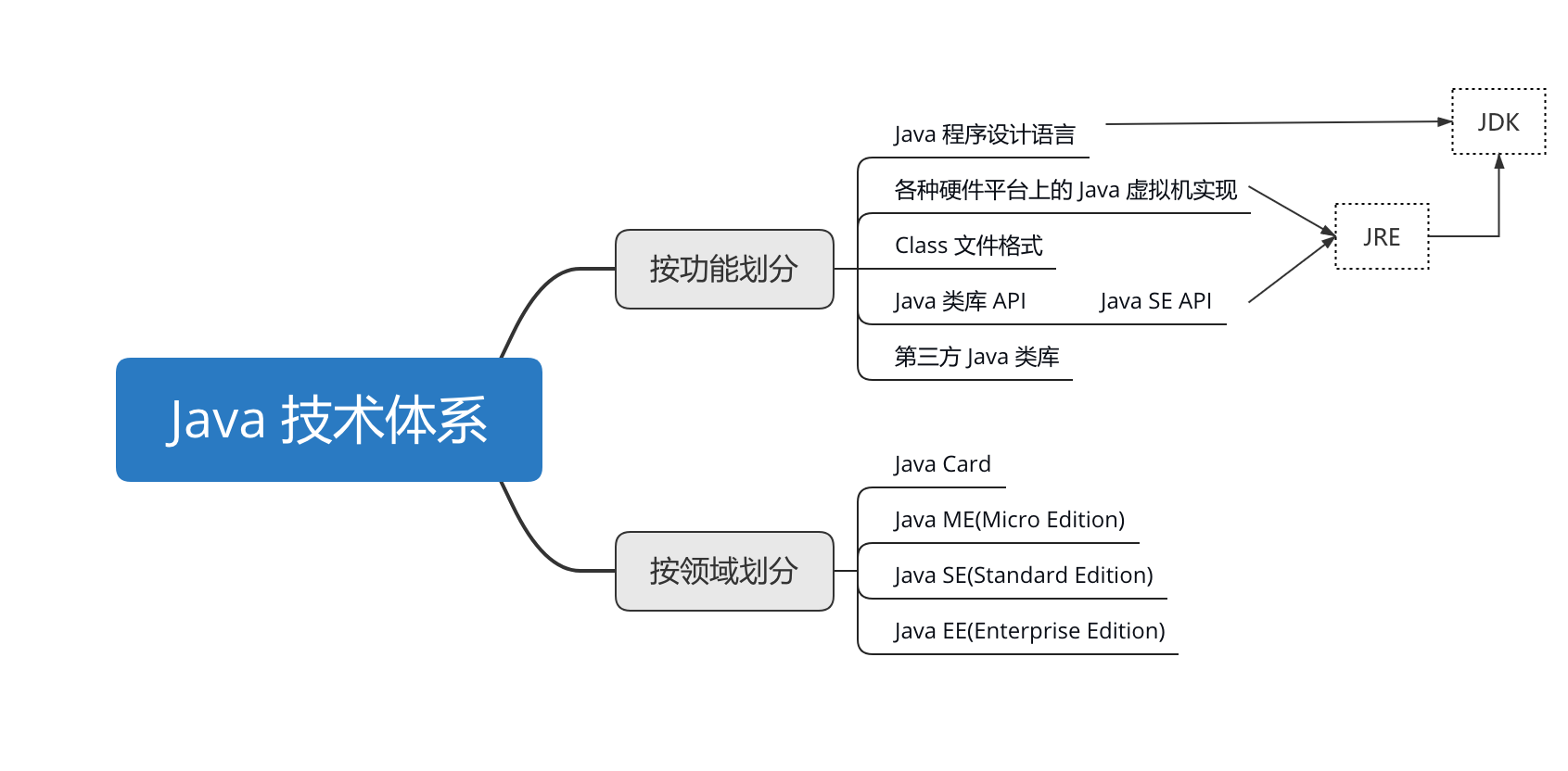
根据 Java 各个组成部分的功能来进行划分
从传统意义上来看,JCP 官方所定义的 Java 技术体系包括了以下几个组成部分:
- Java 程序设计语言
- 各种硬件平台上的 Java 虚拟机实现
- Class 文件格式
- Java 类库 API
- 来自商业机构和开源社区的第三方 Java 类库
Java 程序设计语言、Java 虚拟机、Java 类库这三部分统称为 JDK(Java Development Kit),JDK 是用于支持 Java 程序开发的最小环境。
可以把 Java 类库 API 中的 Java SE API 子集和 Java 虚拟机这两部分统称为 JRE(Java Runtime Environment),JRE 是支持 Java 程序运行的标准环境。

按照技术所服务的领域来或者技术关注的重点业务来划分
Java Card:
支持 Java 小程序(Applets)运行在小内存设备(如智能卡)上的平台。
Java ME(Micro Edition):
支持 Java 程序运行在移动终端(手机、PDA)上的平台,对 Java API 有所精简,并加入了移动终端的针对性支持,这条产品线在 JDK 6 以前被称为J2ME。
有一点读者请勿混淆,现在在智能手机上非常流行的、主要使用 Java 语言开发程序的 Android 并不属于 Java ME。
Java SE(Standard Edition):
支持面向桌面级应用(如Windows下的应用程序)的Java平台,提供了完整的 Java 核心 API,这条产品线在 JDK 6 以前被称为 J2SE。
Java EE(Enterprise Edition):
支持使用多层架构的企业应用(如ERP、MIS、CRM应用)的 Java平台,除了提供 Java SE API 外,还对其做了大量有针对性的扩充,并提供了相关的部署支持,这条产品线在 JDK 6 以前被称为J2EE,在 JDK 10 以后被 Oracle 放弃,捐献给Eclipse基金会管理,此后被称为 Jakarta EE。
1.3 Java发展史
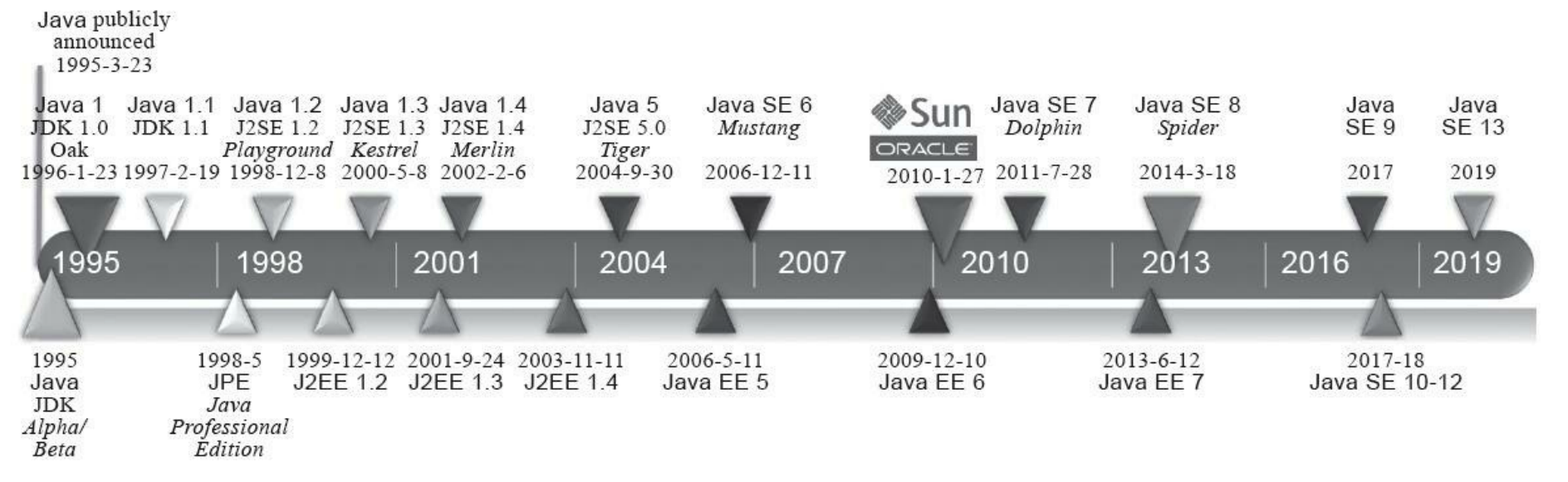
1991年4月,由 James Gosling 博士领导的绿色计划(Green Project)开始启动,这个计划的产品就是Java语言的前身:Oak(得名于James Gosling办公室外的一棵橡树)。
1995年5月23日,Oak语言改名为 Java,并且在 SunWorld 大会上正式发布 Java 1.0 版本。Java 语言第一次提出了 “Write Once,Run Anywhere” 的口号。
1996年1月23日,JDK 1.0发布,Java语言有了第一个正式版本的运行环境。JDK 1.0提供了一个纯解释执行的Java虚拟机实现(Sun Classic VM)。
1996年4月,十个最主要的操作系统和计算机供应商声明将在其产品中嵌入Java技术。
在1996年5月底,Sun于美国旧金山举行了首届JavaOne大会,从此JavaOne成为全世界数百万Java语言开发者每年一度的技术盛会。
1997年2月19日,Sun公司发布了JDK 1.1,Java里许多最基础的技术支撑点(如JDBC等)都是在 JDK 1.1版本中提出的。
1998年12月4日,JDK迎来了一个里程碑式的重要版本:工程代号为Playground(竞技场)的JDK 1.2,Sun在这个版本中把Java技术体系拆分为三个方向,分别是面向桌面应用开发的J2SE(Java 2 Platform,Standard Edition)、面向企业级开发的J2EE(Java 2 Platform,Enterprise Edition)和面向手机等移动终端开发的J2ME(Java 2 Platform,Micro Edition)。
在1999年3月和7月,分别有 JDK 1.2.1和JDK 1.2.2两个小升级版本发布。
1999年4月27日,HotSpot虚拟机诞生。
2000年5月8日,工程代号为Kestrel(美洲红隼)的JDK 1.3发布。
2002年2月13日,JDK 1.4发布,工程代号为Merlin(灰背隼)。JDK 1.4是标志着Java真正走向成熟的一个版本,Compaq、Fujitsu、SAS、Symbian、IBM等著名公司都有参与功能规划,甚至实现自己独立发行的JDK 1.4。
JDK 1.4有两个后续修正版:2002年9月16日发布的工程代号为Grasshopper(蚱蜢)的JDK 1.4.1与2003年6月26日发布的工程代号为Mantis(螳螂) 的JDK 1.4.2。
2002年前后还发生了一件与Java没有直接关系,但事实上对Java的发展进程影响很大的事件,就是微软的.NET Framework发布。这个无论是技术实现还是目标用户上都与Java有很多相近之处的技术平台给Java带来了很多讨论、比较与竞争,.NET平台和Java平台之间声势浩大的孰优孰劣的论战到今天为止都仍然没有完全平息。
2004年9月30日,JDK 5发布,工程代号为Tiger(老虎)。
2006年12月11日,JDK 6发布,工程代号为Mustang(野马)。在这个版本中,Sun公司终结了从 JDK 1.2开始已经有八年历史的J2EE、J2SE、J2ME的产品线命名方式,启用Java EE 6、Java SE 6、Java ME 6的新命名来代替。
在2006年11月13日的JavaOne大会上,Sun公司宣布计划要把Java开源。
2009年2月19日,工程代号为Dolphin(海豚)的JDK 7完成了其第一个里程碑版本。
2009年4月20日,Oracle宣布正式以74亿美元的价格收购市值曾超过2000亿美元的Sun公司,传奇的Sun Microsystems从此落幕成为历史,Java商标正式划归Oracle所有(Java语言本身并不属于哪间公司所有,它由JCP组织进行管理,尽管在JCP中Sun及后来的Oracle的话语权很大)。
2017年9月21日 JDK9 得以艰难面世。
2018年3月20日,JDK 10如期发布。
2018年3月27日,Android的Java侵权案有了最终判决,法庭裁定Google赔偿Oracle合计88亿美元。
2018年10月,最后一届 JavaOne 2018在旧金山举行。
2018年9月25日,JDK 11发布。
2019年3月20日,JDK 12发布。
1.4 Java虚拟机家族
1.4.1 虚拟机始祖:Sun Classic/Exact VM
Sun Classic 虚拟机,“世界上第一款商用Java虚拟机”。1996年1月23日,Sun发布 JDK 1.0,Java语言首次拥有了商用的正式运行环境,这个JDK中所带的
虚拟机就是Classic VM。这款虚拟机只能使用纯解释器方式来执行Java代码,如果要使用即时编译器那就必须进行外挂,但是假如外挂了即时编译器的话,即时编译器就会完全接管虚拟机的执行系统,解释器便不能再工作了。
由于解释器和编译器不能配合工作,这就意味着如果要使用编译执行,编译
器就不得不对每一个方法、每一行代码都进行编译,而无论它们执行的频率是否具有编译的价值。基于程序响应时间的压力,这些编译器根本不敢应用编译耗时稍高的优化技术,因此这个阶段的虚拟机虽然用了即时编译器输出本地代码,其执行效率也和传统的C/C++程序有很大差距,“Java语言很慢”的印象就是在这阶段开始在用户心中树立起来的。
在JDK 1.2时,曾在Solaris平台上发布过一款名为Exact VM的虚拟机,它的编译执行系统已经具备现代高性能虚拟机雏形,如热点探测、两级即时编译器、编译器与解释器混合工作模式等。
Exact VM因它使用准确式内存管理(Exact Memory Management,也可以叫Non-Conservative/Accurate Memory Management)而得名。准确式内存管理是指虚拟机可以知道内存中某个位置的数据具体是什么类型。譬如内存中有一个32bit的整数123456,虚拟机将有能力分辨出它到底是一个指向了123456的内存地址的引用类型还是一个数值为123456的整数。由于使用了准确式内存管理,Exact VM可以抛弃掉以前Classic VM基于句柄(Handle)的对象查找方式这样每次定位对象都少了一次间接查找的开销,显著提升执行性能。
虽然Exact VM的技术相对Classic VM来说先进了许多,但是它的命运显得十分英雄气短,在商业应用上只存在了很短暂的时间就被外部引进的HotSpotVM所取代,甚至还没有来得及发布Windows和Linux平台下的商用版本。而Classic VM的生命周期则相对要长不少,它在JDK 1.2之前是JDK中唯一的虚拟机,在JDK 1.2时,它与HotSpot VM并存,但默认是使用Classic VM(用户可用java-hotspot参数切换至HotSpot VM),而在JDK 1.3时,HotSpot VM成为默认虚拟机,它仍作为虚拟机的“备用选择”发布(使用java-classic参数切换),直到JDK 1.4的时候,Classic VM才完全退出商用虚拟机的历史舞台,与Exact VM一起进入了Sun Labs Research VM之中。
1.4.2 武林盟主:HotSpot VM
相信所有Java程序员都听说过HotSpot虚拟机,它是Sun/OracleJDK和OpenJDK中的默认Java虚拟机,也是目前使用范围最广的Java虚拟机。
这个在今天看起来“血统纯正”的虚拟机在最初并非由Sun公司所开发,而是由一家名为“Longview Technologies”的小公司设计;Sun公司注意到这款虚拟机在即时编译等多个方面有着优秀的理念和实际成果,在1997年收购了Longview Technologies公司,从而获得了HotSpot虚拟机。
HotSpot既继承了Sun之前两款商用虚拟机的优点,也有许多自己新的技术优势,如它名称中的HotSpot指的就是它的热点代码探测技术,HotSpot虚拟机的热点代码探测能力可以通过执行计数器找出最具有编译价值的代码,然后通知即时编译器以方法为单位进行编译。如果一个方法被频繁调用,或方法中有效循环次数很多,将会分别触发标准即时编译和栈上替换编译(On-StackReplacement,OSR)行为。
1.4.3 小家碧玉:Mobile/Embedded VM
面对移动和嵌入式市场,有专门的Java虚拟机产品。Oracle公司在Java ME这条产品线上的虚拟机名为CDC-HI(C Virtual Machine,CVM)和CLDC-HI(Monty VM)。其中CDC/CLDC全称是Connected(Limited)Device Configuration,后面的HI则是HotSpot Implementation的缩写。
1.4.4 天下第二:BEA JRockit/IBM J9 VM
除了Sun/Oracle公司以外,也有其他组织、公司开发过虚拟机的实现。如果说HotSpot是天下第一的武林盟主,那曾经与HotSpot并称“三大商业Java虚拟机”的另外两位,毫无疑问就该是天下第二了,它们分别是BEA System公司的JRockit与IBM公司的IBM J9。
JRockit随着BEA被Oracle收购,现已不再继续发展,永远停留在R28版本,这是JDK 6版JRockit的代号。
1.4.5 软硬合璧:BEA Liquid VM/Azul VM
我们平时所提及的“高性能Java虚拟机”一般是指HotSpot、JRockit、J9这类在通用硬件平台上运行 的商用虚拟机,但其实还有一类与特定硬件平台绑定、软硬件配合工作的专有虚拟机,往往能够实现更高的执行性能,或提供某些特殊的功能特性。这类专有虚拟机的代表是BEA Liquid VM和Azul VM。
Liquid VM也被称为JRockit VE(Virtual Edition,VE),它是BEA公司开发的可以直接运行在自家 Hypervisor系统上的JRockit虚拟机的虚拟化版本。随着JRockit虚拟机终止开发,Liquid VM 项目也已经停止了。
Azul VM是Azul Systems公司在HotSpot基础上进行大量改进,运行于Azul Systems公司的专有硬件Vega系统上的Java虚拟机。随着虚拟机技术的不断发展,Java虚拟机变得越来越强大的同时也越来越复杂,要推动在专有硬件上的Java虚拟机升级发展,难以直接借助开源社区的力量,往往需要耗费更高昂的成本,在商业上的缺陷使得专有虚拟机逐渐没落,Azul Systems公司最终也放弃了Vega产品线,把全部精力投入到Zing 和Zulu产品线中。
Zing虚拟机是一个从HotSpot某旧版代码分支基础上独立出来重新开发的高性能Java虚拟机,在要求低延迟、快速预热等场景中,Zing VM都要比HotSpot表现得更好。Zing的PGC、 C4收集器可以轻易支持TB级别的Java堆内存,而且保证暂停时间仍然可以维持在不超过10毫秒的范围里,HotSpot要一直到JDK 11和JDK 12的ZGC及Shenandoah收集器才达到了相同的目标,而且目前效果仍然远不如C4。Zing的ReadyNow功能可以利用之前运行时收集到的性能监控数据,引导虚拟机在启动后快速达到稳定的高性能水平,减少启动后从解释执行到即时编译的等待时间。Zing自带的 ZVision/ZVRobot功能可以方便用户监控Java虚拟机的运行状态,从找出代码热点到对象分配监控、锁 竞争监控等。Zing能让普通用户无须了解垃圾收集等底层调优,就可以使得Java应用享有低延迟、快速预热、易于监控的功能,这是Zing的核心价值和卖点,很多Java应用都可以通过长期努力在应用、 框架层面优化来提升性能,但使用Zing的话就可以把精力更多集中在业务方面。
1.4.6 挑战者:Apache Harmony/Google Android Dalvik VM
Harmony虚拟机(准确地说是Harmony里的DRLVM)和Dalvik虚拟机只能称作“虚拟机”,而不能称作“Java虚拟机”,Apache Harmony是一个Apache软件基金会旗下以Apache License协议开源的实际兼容于JDK 5和 JDK 6的Java程序运行平台,它含有自己的虚拟机和Java类库API,用户可以在上面运行Eclipse、 Tomcat、Maven等常用的Java程序。但是,它并没有通过TCK认证,所以我们不得不用一长串冗长拗口的语言来介绍它,而不能用一句“Apache的JDK”或者“Apache的Java虚拟机”来直接代指。 如果一个公司要宣称自己的运行平台“兼容于Java技术体系”,那该运行平台就必须要通过 TCK(Technology Compatibility Kit)的兼容性测试,Apache基金会曾要求当时的Sun公司提供TCK的使用授权,但是一直遭到各种理由的拖延和搪塞,直到Oracle收购了Sun公司之后,双方关系越闹越僵,最终导致Apache基金会愤然退出JCP组织,这是Java社区有史以来最严重的分裂事件之一。
Dalvik虚拟机曾经是Android平台的核心组成部分之一。Dalvik虚拟机并不是一个Java虚拟机,它没有遵循《Java虚拟机规范》,不能直接执行Java的 Class文件,使用寄存器架构而不是Java虚拟机中常见的栈架构。但是它与Java却又有着千丝万缕的联系,它执行的DEX(Dalvik Executable)文件可以通过Class文件转化而来,使用Java语法编写应用程序,可以直接使用绝大部分的Java API等。在Android发展的早期,Dalvik虚拟机随着Android的成功迅速流行,在Android 2.2中开始提供即时编译器实现,执行性能又有了进一步提高。不过到了Android 4.4时代,支持提前编译(Ahead of Time Compilation,AOT)的ART虚拟机迅速崛起,在当时性能还不算特别强大的移动设备上,提前编译要比即时编译更容易获得高性能,所以在Android 5.0里ART就全面代替了Dalvik虚拟机。
1.4.7 没有成功,但并非失败:Microsoft JVM及其他
在Java语言诞生的初期(1996年~1998年,以JDK1.2发布之前为分界),它的主要应用之一是在浏览器中运行Java Applets程序,微软为了在Internet Explorer 3浏览器中支持Java Applets应用而开发了自己的Java虚拟机,在1997年10月,Sun公司正式以侵犯商标、不正当竞争等罪名控告微软,官司的结果是微软向Sun公司(最终微软因垄断赔偿给Sun公司的总金额高达10亿美元)赔偿2000万美金,承诺终止其Java虚拟机的发展,并逐步在产品中移除Java虚拟机相关功能。而最令人感到讽刺的是,到后来在 Windows XP SP3 中Java虚拟机被完全抹去的时候,Sun公司却又到处登报希望微软不要这样做。Windows XP高级产品经理Jim Cullinan称:“我们花费了三年的时间和Sun公司打官司,当时他们试图阻止我们在Windows中支持Java,现在我们这样做了,可他们又在抱怨,这太具有讽刺意味了。” 我们试想一下,如果当年Sun公司没有起诉微软公司,微软继续保持着对Java技术的热情,那 Java 的世界会变得更好还是更坏?.NET技术是否还会发展起来?
1.4.8 百家争鸣
还有一些Java虚拟机天生就注定不会应用在主流领域,或者不是单纯为了用于生产,甚至在设计之初就没有抱着商用的目的,仅仅是用于研究、验证某种技术和观点,又或者是作为一些规范的标准实现。
KVM
Java Card VM
Squawk VM
JavaInJava
Maxine VM
Jikes RVM
IKVM.NET
1.5 展望Java技术的未来
1.5.1 无语言倾向
2018年4月,Oracle Labs新公开了一项黑科技:Graal VM,从它的口号“Run Programs Faster Anywhere”就能感觉到一颗蓬勃的野心,这句话显然是与1995年Java刚诞生时的“Write Once,Run Anywhere”在遥相呼应。
Graal VM被官方称为“Universal VM”和“Polyglot VM”,这是一个在HotSpot虚拟机基础上增强而成的跨语言全栈虚拟机,可以作为“任何语言”的运行平台使用,这里“任何语言”包括了Java、Scala、 Groovy、Kotlin等基于Java虚拟机之上的语言,还包括了C、C++、Rust等基于LLVM的语言,同时支持其他像JavaScript、Ruby、Python和R语言等。Graal VM可以无额外开销地混合使用这些编程语言, 支持不同语言中混用对方的接口和对象,也能够支持这些语言使用已经编写好的本地库文件。
如果Java语言或者 HotSpot虚拟机真的有被取代的一天,那从现在看来Graal VM是希望最大的一个候选项,这场革命很可能会在Java使用者没有明显感觉的情况下悄然而来,Java世界所有的软件生态都没有发生丝毫变化, 但天下第一的位置已经悄然更迭。
1.5.2 新一代即时编译器
HotSpot虚拟机中含有两个即时编译器,分别是编译耗时短但输出代码优化程度较低的客户端编译器(简称为C1)以及编译耗时长但输出代码优化质量也更高的服务端编译器(简称为C2),通常它们会在分层编译机制下与解释器互相配合来共同构成HotSpot虚拟机的执行子系统
自JDK 10起,HotSpot中又加入了一个全新的即时编译器:Graal编译器。Graal编译器是以C2编译器替代者的身份登场的。Graal能够做比C2更加复杂的优化,如“部分逃逸分析”(Partial Escape Analysis),也拥有比C2更容易使用激进预测性优化(Aggressive Speculative Optimization)的策略,支持自定义的预测性假设等。
今天的Graal编译器尚且年幼,还未经过足够多的实践验证,所以仍然带着“实验状态”的标签,需要用开关参数去激活。Graal编译器未来的前途可期,作为Java虚拟机执行代码的最新引擎,它的持续改进,会同时为 HotSpot与Graal VM注入更快更强的驱动力。
1.5.3 向Native迈进
在微服务架构的视角下,应用拆分后,单个微服务很可能就不再需要面对数十、数百GB乃至TB的内存,有了高可用的服务集群,也无须追求单个服务要7×24小时不间断地运行,它们随时可以中断和更新。
Java的启动时间相对较长,需要预热才能达到最高性能等特点就显得相悖于这样的应用场景。
在无服务架构中,矛盾则可能会更加突出,比起服务,一个函数的规模通常会更小,执行时间会更短,当前最热门的无服务运行环境AWS Lambda所允许的最长运行时间仅有15分钟。
一直把软件服务作为重点领域的Java自然不可能对此视而不见,在最新的几个JDK版本的功能清单中,已经陆续推出了跨进程的、可以面向用户程序的类型信息共享(Application Class Data Sharing,AppCDS,允许把加载解析后的类型信息缓存起来,从而提升下次启动速度,原本CDS只支持Java标准库,在JDK 10时的AppCDS开始支持用户的程序代码)、无操作的垃圾收集器(Epsilon, 只做内存分配而不做回收的收集器,对于运行完就退出的应用十分合适)等改善措施。而酝酿中的一个更彻底的解决方案,是逐步开始对提前编译(Ahead of Time Compilation,AOT)提供支持。
提前编译是相对于即时编译的概念。
早在JDK 9时期,Java就提供了实验性的Jaotc命令来进行提前编译,不过多数人试用过后都颇感失望。直到Substrate VM出现,才算是满足了人们心中对Java提前编译的全部期待。
Substrate VM是在 Graal VM 0.20版本里新出现的一个极小型的运行时环境,目标是代替HotSpot用来支持提前编译后的程序执行。
Substrate VM带来的好处是能显著降低内存占用及启动时间。根据Oracle官方给出的测试数据,运行在Substrate VM上的小规模应用, 其内存占用和启动时间与运行在HotSpot上相比有5倍到50倍的下降。
Substrate VM补全了Graal VM“Run Programs Faster Anywhere”愿景蓝图里的最后一块拼图,让 Graal VM支持其他语言时不会有重量级的运行负担。譬如运行JavaScript代码,Node.js的V8引擎执行效率非常高,但即使是最简单的HelloWorld,它也要使用约20MB的内存,而运行在Substrate VM上的Graal.js,跑一个HelloWorld则只需要4.2MB内存,且运行速度与V8持平。Substrate VM的轻量特性,使得它十分适合嵌入其他系统,譬如Oracle自家的数据库就已经开始使用这种方式支持用不同的语言代替PL/SQL来编写存储过程。
提前编译的好处:
Java虚拟机加载这些已经预编译成二进制库之后就能够直接调用,而无须再等待即时编译器在运行时将其编译成二进制机器码。
提前编译的坏处:
破坏了Java“一次编写,到处运行”的承诺,必须为每个不同的硬件、操作系统去编译对应的发行包;
降低了Java链接过程的动态性,必须要求加载的代码在编译期就是全部已知的,而不能在运行期才确定,否则就只能舍弃掉已经提前编译好的版本,退回到原来的即时编译执行状态。
1.5.4 灵活的胖子
二十年间有无数改进和功能被不断地添加到HotSpot的源代码上,致使它成长为今天这样的庞然大物。 HotSpot的定位是面向各种不同应用场景的全功能Java虚拟机,这是一个极高的要求,仿佛是让一个胖子能拥有敏捷的身手一样的矛盾。
HotSpot开发团队正在持续地重构着HotSpot的架构,让它具有模块化的能力和足够的开放性。模块化方面原本是HotSpot的弱项,监控、执行、编译、内存管理等多个子系统的代码相互纠缠。
BM的J9就一直做得就非常好,面向Java ME的J9虚拟机与面向Java EE的J9虚拟机可以是完全由同一套代码库编译出来的产品,只有编译时选择的模块配置有所差别。
现在,HotSpot虚拟机也有了与J9类似的能力,能够在编译时指定一系列特性开关,让编译输出的 HotSpot 虚拟机可以裁剪成不同的功能,譬如支持哪些编译器,支持哪些收集器,是否支持JFR、 AOT、CDS、NMT等都可以选择。能够实现这些功能特性的组合拆分,反映到源代码不仅仅是条件编译,更关键的是接口与实现的分离。
早期(JDK 1.4时代及之前)的HotSpot虚拟机为了提供监控、调试等不会在《Java虚拟机规范》 中约定的内部功能和数据,就曾开放过Java虚拟机信息监控接口(Java Virtual Machine Profiler Interface,JVMPI)与Java虚拟机调试接口(Java Virtual Machine Debug Interface,JVMDI)供运维和性能监控、IDE等外部工具使用。
到了JDK 5时期,又抽象出了层次更高的Java虚拟机工具接口(Java Virtual Machine Tool Interface,JVMTI)来为所有Java虚拟机相关的工具提供本地编程接口集合,到 JDK 6时JVMTI就完全整合代替了JVMPI和JVMDI的作用。
在JDK 9时期,HotSpot虚拟机开放了Java语言级别的编译器接口(Java Virtual Machine Compiler Interface,JVMCI),使得在Java虚拟机外部增加、替换即时编译器成为可能,这个改进实现起来并不费劲,但比起之前JVMPI、JVMDI和JVMTI却是更深层次的开放,它为不侵入HotSpot代码而增加或修改HotSpot虚拟机的固有功能逻辑提供了可行性。Graal编译器就是通过这个接口植入到HotSpot之中。
到了JDK 10,HotSpot又重构了Java虚拟机的垃圾收集器接口(Java Virtual Machine Compiler Interface),统一了其内部各款垃圾收集器的公共行为。有了这个接口,才可能存在日后(今天尚未) 某个版本中的CMS收集器退役,和JDK 12中Shenandoah这样由Oracle以外其他厂商领导开发的垃圾收集器进入HotSpot中的事情。如果未来这个接口完全开放的话,甚至有可能会出现其他独立于HotSpot 的垃圾收集器实现。 经过一系列的重构与开放,HotSpot虚拟机逐渐从时间的侵蚀中挣脱出来,虽然代码复杂度还在增长,体积仍在变大,但其架构并未老朽,而是拥有了越来越多的开放性和扩展性,使得HotSpot成为一个能够联动外部功能,能够应对各种场景,能够学会十八般武艺的身手灵活敏捷的“胖子”。
1.5.5 语言语法持续增强
一门语言的功能、语法是影响语言生产力和效率的重要因素,很多语言特性和语法糖不论有没有,程序也照样能写,但即使只是可有可无的语法糖,也是直接影响语言使用者的幸福感程度的关键指标。
JDK 7的Coins项目结束以后,Java社区又创建了另外一个新的语言特性改进项目Amber,JDK 10至13里面提供的新语法改进基本都来自于这个项目,譬如:
- JEP 286:Local-Variable Type Inference,在JDK 10中提供,本地类型变量推断。
- JEP 323:Local-Variable Syntax for Lambda Parameters,在JDK 11中提供,JEP 286的加强,使它可以用在Lambda中。
- JEP 325:Switch Expressions,在JDK 13中提供,实现switch语句的表达式支持。
- JEP 335:Text Blocks,在JDK 13中提供,支持文本块功能,可以节省拼接HTML、SQL等场景里 大量的“+”操作。
还有一些是仍然处于草稿状态或者暂未列入发布范围的JEP,可供我们窥探未来Java语法的变化, 譬如:
- JEP 301:Enhanced Enums,允许常量类绑定数据类型,携带额外的信息。
- JEP 302:Lambda Leftovers,用下划线来表示Lambda中的匿名参数。
- JEP 305:Pattern Matching for instanceof,用instanceof判断过的类型,在条件分支里面可以不需要做强类型转换就能直接使用。
除语法糖以外,语言的功能也在持续改进之中,以下几个项目是目前比较明确的,也是受到较多关注的功能改进计划:
- Project Loom:现在的Java做并发处理的最小调度单位是线程,Java线程的调度是直接由操作系统内核提供的,会有核心态、用户态的切换开销。而很多其他语言都提供了更加轻量级的、由软件自身进行调度的用户线程,譬如 Golang的Groutine、D语言的Fiber等。Loom项目就准备提供一套与目前Thread类API非常接近的Fiber实现。
- Project Valhalla:提供值类型和基本类型的泛型支持,并提供明确的不可变类型和非引用类型的声明。不可变类型在并发编程中能带来很多好处,没有数据竞争风险带来了更好的性能。一些语言(如Scala)就有明确的不可变类型声明,而Java中只能在定义类时将全部字段声明为final来间接实现。基本类型的范型支持是指在泛型中引用基本数据类型不需要自动装箱和拆箱,避免性能损耗。
- Project Panama:目的是消弭Java虚拟机与本地代码之间的界线。现在Java代码可以通过JNI来调用本地代码,这点在与硬件交互频繁的场合尤其常用(譬如Android)。但是JNI的调用方式充其量只能说是达到能用的标准而已,使用起来仍相当烦琐,频繁执行的性能开销也非常高昂,Panama项目的目标就是提供更好的方式让Java代码与本地代码进行调用和传输数据。
1.6 实战:自己编译JDK
1.6.1 获取源码
OpenJDK 12:https://hg.openjdk.java.net/jdk/jdk12/
然后点击左边菜单中的“Browse”,此时点击左边的“zip”链接即可下载当前版本打包好的源码,到本地直接解压即可。
1.6.2 系统需求
建议尽量在Linux或者MacOS上构建OpenJDK,这两个系统在准备构建工具链和依赖项上要比在Windows或Solaris平台上要容易许多。
无论在什么平台下进行编译,都建议读者认真阅读一遍源码中的doc/building.html文档。
本次编译中采用的是64位操作系统,默认参数下编译出来的也是64位的OpenJDK。在官方文档上要求编译OpenJDK至少需要2~4GB的内存空间,而且至少要6~8GB的空闲磁盘空间,不要看OpenJDK源码的大小只有不到600MB,要完成编译,过程中会产生大量的中间文件,并且编译出不同优化级别(Product、FastDebug、SlowDebug)的HotSpot虚拟机可能要重复生成这些中间文件,这都会占用大量磁盘空间。
所有的文件,包括源码和依赖项目,都不要放在包含中文的目录里面。
1.6.3 构建编译环境
| 工具 | 库名称 | 安装命令 |
|---|---|---|
| FreeType | The FreeType Project | sudo apt-get install libfreetype6-dev |
| CUPS | Common UNIX Printing System | sudo apt-get install libcups2-dev |
| X11 | X Window System | sudo apt-get install libx11-dev libxext-dev libxrender-dev libxrandr-dev libxtst-dev libxt-dev |
| ALSA | Advanced Linux Sound Architecture | sudo apt-get install libasound2-dev |
| libffi | Portable Foreign Function Interface Library | sudo apt-get install libffi-dev |
| Autoconf | Extensible Package of M4 Macros | sudo apt-get install autoconf |
要编译大版本号为N的JDK,还要另外准备一个大版本号至少为N-1的、已经编译 好的JDK,这是因为OpenJDK由多个部分构成,其中一部分代码使用C、C++编写,而更多的代码则是使用Java语言来实现,因此编译这些Java代码就需要用到另一个编译期可用的JDK,官方称这个JDK为“Bootstrap JDK”。编译OpenJDK 12时,Bootstrap JDK必须使用JDK 11及之后的版本。在Ubuntu中使用以下命令安装OpenJDK 11:sudo apt-get install openjdk-11-jdk
1.6.4 进行编译
1.6.5 在IDE工具中进行源码调试
1.7 本章小结
第二部分 自动内存管理
第2章 Java内存区域与内存溢出异常
Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,墙外面的人想进去,墙里面的人却想出来。
2.1 概述
对于从事C、C++程序开发的开发人员来说,在内存管理领域,他们既是拥有最高权力的“皇帝”, 又是从事最基础工作的劳动人民——既拥有每一个对象的“所有权”,又担负着每一个对象生命从开始到终结的维护责任。
Java虚拟机自动内存管理机制的优缺点
优点:不再需要为每一个new操作去写配对的内存分配回收代码,不容易出现内存泄漏和内存溢出问题。
缺点:由于把控制内存的权力交给了Java虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那排查错误、修正问题将会成为一项异常艰难的工作。
2.2 运行时数据区域
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间。根据《Java虚拟机规范》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域。
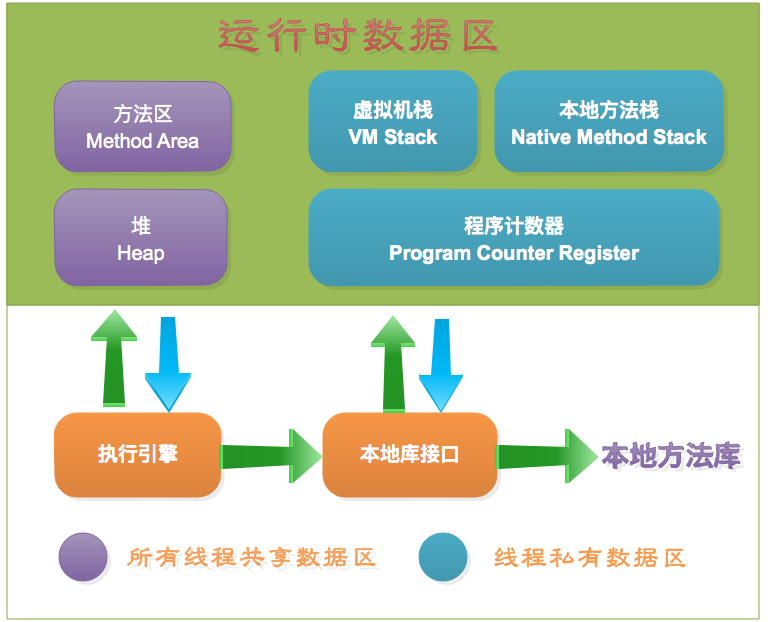
2.2.1 程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。
字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是本地(Native)方法,这个计数器值则应为空(Undefined)。
此内存区域是唯一一个在《Java虚拟机规范》中没有规定任何OutOfMemoryError情况的区域。
为什么程序计数器是线程私有的?
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储。
2.2.2 Java虚拟机栈
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stack)也是线程私有的,它的生命周期与线程相同。
虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种Java虚拟机基本数据类型、对象引用(可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress 类型(指向了一条字节码指令的地址)。
局部变量表中的存储空间以局部变量槽(Slot)来表示,其中64位长度的long和 double类型的数据会占用两个变量槽,其余的数据类型只占用一个。
局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在《Java虚拟机规范》中,对这个内存区域规定了两类异常状况:
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;
如果Java虚拟机栈容量可以动态扩展,当栈扩 展时无法申请到足够的内存会抛出OutOfMemoryError异常。
HotSpot虚拟机的栈容量是不可以动态扩展的,以前的Classic虚拟机倒是可以。所以在HotSpot虚拟机上是不会由于虚拟机栈无法扩展而导致OutOfMemoryError异常——只要线程申请栈空间成功了就不会有OOM,但是如果申请时就失败,仍然是会出现OOM异常的。
2.2.3 本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈的区别:
虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native) 方法服务。
《Java虚拟机规范》对本地方法栈中方法使用的语言、使用方式与数据结构并没有任何强制规定,因此Hot-Spot虚拟机直接就把本地方法栈和虚拟机栈合二为一。
与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
2.2.4 Java堆
Java堆(Java Heap)是虚拟机所管理的内存中最大的一块。
Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。
此内存区域的唯一目的就是存放对象实例。
Java堆是垃圾收集器管理的内存区域,因此也被称作“GC堆”(Garbage Collected Heap)。
从回收内存的角度看,由于现代垃圾收集器大部分都是基于分代收集理论设计的,所以Java堆中经常会出现“新生代”、“老年代”、“永久代”、“Eden空间”、“From Survivor空 间”、“To Survivor空间”等名词。
从分配内存的角度看,所有线程共享的Java堆中可以划分出多个线程私有的分配缓冲区 (Thread Local Allocation Buffer,TLAB),以提升对象分配时的效率。
根据《Java虚拟机规范》的规定,Java堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。但对于大对象(典型的如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的内存空间。
主流的Java虚拟机都是按照可扩展来实现的。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
Java对象实例都分配在堆上吗?
Java 世界里“几乎”所有的对象实例都在这里分配内存。在《Java虚拟机规范》中对Java堆的描述是:“所有的对象实例以及数组都应当在堆上分配”。
随着Java语言的发展,现在已经能看到些许迹象表明日后可能出现值类型的支持,即使只考虑现在,由于即时编译技术的进步,尤其是逃逸分析技术的日渐强大,栈上分配、标量替换优化手段已经导致一些微妙的变化悄然发生,所以说Java对象实例都分配在堆上也渐渐变得不是那么绝对了。
如果对一个对象进行逃逸分析,发现其作用范围并不会超出一个方法,那就可以直接将该对象分配在栈空间,如果发现只使用了该对象的个别成员变量,那就可以将该对象拆开,将使用到的成员变量转变为局部变量。
Java堆中一定存在年轻代、老年代或永久代吗?
Java堆是否被划分为年轻代、老年代和永久代,取决于Java虚拟机所使用的垃圾收集器是否按照经典的分代收集理论来设计的,即虚拟机采用了按分代收集理论设计的垃圾收集器时才会被划分为年轻代、老年代和永久代。
这样的区域划分仅仅是一部分垃圾收集器的共同特性或者说设计风格而已,而非某个Java虚拟机具体实现的固有内存布局,更不是《Java虚拟机规范》里对Java堆的进一步细致划分。
在十年之前(以G1收集器的出现为分界),HotSpot虚拟机内部的垃圾收集器全部都基于“经典分代”来设计,需要新生代、老年代收集器搭配才能工作。
但是到了今天,垃圾收集器技术与十年前已不可同日而语,HotSpot里面也出现了不采用分代设计的新垃圾收集器。
2.2.5 方法区
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫作“非堆”(Non-Heap),目的是与Java堆区分开来。
说到方法区,不得不提一下“永久代”这个概念,尤其是在JDK 8以前,许多Java程序员都习惯在 HotSpot虚拟机上开发、部署程序,很多人都更愿意把方法区称呼为“永久代”(Permanent Generation),或将两者混为一谈。本质上这两者并不是等价的,因为仅仅是当时的HotSpot虚拟机设计团队选择把收集器的分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样使得 HotSpot 的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。但是对于其他虚拟机实现,譬如BEA JRockit、IBM J9等来说,是不存在永久代的概念的。原则上如何实现方法区属于虚拟机实现细节,不受《Java虚拟机规范》管束,并不要求统一。但现在回头来看,当年使用永久代来实现方法区的决定并不是一个好主意,这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB限制,就不会出问题),而且有极少数方法 (例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。当Oracle收购BEA获得了 JRockit的所有权后,准备把JRockit中的优秀功能,譬如Java Mission Control管理工具,移植到HotSpot 虚拟机时,但因为两者对方法区实现的差异而面临诸多困难。考虑到HotSpot未来的发展,在JDK 6的 时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了,到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出,而到了 JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Metaspace)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。
方法区于永久代的联系与区别
在JDK 8以前,HotSpot虚拟机设计团队选择把收集器的分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样使得 HotSpot 的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。但是对于其他虚拟机实现,譬如BEA JRockit、IBM J9等来说,是不存在永久代的概念的。
这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB限制,就不会出问题),而且有极少数方法 (例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。当Oracle收购BEA获得了 JRockit的所有权后,准备把JRockit中的优秀功能,譬如Java Mission Control管理工具,移植到HotSpot 虚拟机时,但因为两者对方法区实现的差异而面临诸多困难。考虑到HotSpot未来的发展,
在JDK 6的时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了,到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出,而到了 JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Metaspace)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。
2.2.6 运行时常量池 47
2.2.7 直接内存 47
2.3 HotSpot虚拟机对象探秘 48
2.3.1 对象的创建 48
2.3.2 对象的内存布局 51
2.3.3 对象的访问定位 52
2.4 实战:OutOfMemoryError异常 53
2.4.1 Java堆溢出 54
2.4.2 虚拟机栈和本地方法栈溢出 56
2.4.3 方法区和运行时常量池溢出 61
2.4.4 本机直接内存溢出 65
2.5 本章小结 66
第3章 垃圾收集器与内存分配策略 67
3.1 概述 67
3.2 对象已死? 68
3.2.1 引用计数算法 68
3.2.2 可达性分析算法 70
3.2.3 再谈引用 71
3.2.4 生存还是死亡? 72
3.2.5 回收方法区 74
3.3 垃圾收集算法 75
3.3.1 分代收集理论 75
3.3.2 标记-清除算法 77
3.3.3 标记-复制算法 78
3.3.4 标记-整理算法 79
3.4 HotSpot的算法细节实现 81
3.4.1 根节点枚举 81
3.4.2 安全点 82
3.4.3 安全区域 83
3.4.4 记忆集与卡表 84
3.4.5 写屏障 85
3.4.6 并发的可达性分析 87
3.5 经典垃圾收集器 89
3.5.1 Serial收集器 90
3.5.2 ParNew收集器 92
3.5.3 Parallel Scavenge收集器 93
3.5.4 Serial Old收集器 94
3.5.5 Parallel Old收集器 95
3.5.6 CMS收集器 96
3.5.7 Garbage First收集器 98
3.6 低延迟垃圾收集器 104
3.6.1 Shenandoah收集器 105
3.6.2 ZGC收集器 112
3.7 选择合适的垃圾收集器 121
3.7.1 Epsilon收集器 121
3.7.2 收集器的权衡 121
3.7.3 虚拟机及垃圾收集器日志 122
3.7.4 垃圾收集器参数总结 127
3.8 实战:内存分配与回收策略 129
3.8.1 对象优先在Eden分配 130
3.8.2 大对象直接进入老年代 131
3.8.3 长期存活的对象将进入老年代 132
3.8.4 动态对象年龄判定 134
3.8.5 空间分配担保 135
3.9 本章小结 137
第4章 虚拟机性能监控、故障处理工具 138
4.1 概述 138
4.2 基础故障处理工具 138
4.2.1 jps:虚拟机进程状况工具 141
4.2.2 jstat:虚拟机统计信息监视工具 142
4.2.3 jinfo:Java配置信息工具 143
4.2.4 jmap:Java内存映像工具 144
4.2.5 jhat:虚拟机堆转储快照分析工具 145
4.2.6 jstack:Java堆栈跟踪工具 146
4.2.7 基础工具总结 148
4.3 可视化故障处理工具 151
4.3.1 JHSDB:基于服务性代理的调试工具 152
4.3.2 JConsole:Java监视与管理控制台 157
4.3.3 VisualVM:多合-故障处理工具 164
4.3.4 Java Mission Control:可持续在线的监控工具 171
4.4 HotSpot虚拟机插件及工具 175
4.5 本章小结 180
第5章 调优案例分析与实战 181
5.1 概述 181
5.2 案例分析 181
5.2.1 大内存硬件上的程序部署策略 182
5.2.2 集群间同步导致的内存溢出 184
5.2.3 堆外内存导致的溢出错误 185
5.2.4 外部命令导致系统缓慢 187
5.2.5 服务器虚拟机进程崩溃 187
5.2.6 不恰当数据结构导致内存占用过大 188
5.2.7 由Windows虚拟内存导致的长时间停顿 189
5.2.8 由安全点导致长时间停顿 190
5.3 实战:Eclipse运行速度调优 192
5.3.1 调优前的程序运行状态 193
5.3.2 升级JDK版本的性能变化及兼容问题 196
5.3.3 编译时间和类加载时间的优化 200
5.3.4 调整内存设置控制垃圾收集频率 203
5.3.5 选择收集器降低延迟 206
5.4 本章小结 209
第三部分 虚拟机执行子系统
第6章 类文件结构 212
6.1 概述 212
6.2 无关性的基石 212
6.3 Class类文件的结构 214
6.3.1 魔数与Class文件的版本 215
6.3.2 常量池 218
6.3.3 访问标志 224
6.3.4 类索引、父类索引与接口索引集合 225
6.3.5 字段表集合 226
6.3.6 方法表集合 229
6.3.7 属性表集合 230
6.4 字节码指令简介 251
6.4.1 字节码与数据类型 251
6.4.2 加载和存储指令 253
6.4.3 运算指令 254
6.4.4 类型转换指令 255
6.4.5 对象创建与访问指令 256
6.4.6 操作数栈管理指令 256
6.4.7 控制转移指令 257
6.4.8 方法调用和返回指令 257
6.4.9 异常处理指令 258
6.4.10 同步指令 258
6.5 公有设计,私有实现 259
6.6 Class文件结构的发展 260
6.7 本章小结 261
第7章 虚拟机类加载机制 262
7.1 概述 262
7.2 类加载的时机 263
7.3 类加载的过程 267
7.3.1 加载 267
7.3.2 验证 268
7.3.3 准备 271
7.3.4 解析 272
7.3.5 初始化 277
7.4 类加载器 279
7.4.1 类与类加载器 280
7.4.2 双亲委派模型 281
7.4.3 破坏双亲委派模型 285
7.5 Java模块化系统 287
7.5.1 模块的兼容性 288
7.5.2 模块化下的类加载器 290
7.6 本章小结 292
第8章 虚拟机字节码执行引擎 293
8.1 概述 293
8.2 运行时栈帧结构 294
8.2.1 局部变量表 294
8.2.2 操作数栈 299
8.2.3 动态连接 300
8.2.4 方法返回地址 300
8.2.5 附加信息 301
8.3 方法调用 301
8.3.1 解析 301
8.3.2 分派 303
8.4 动态类型语言支持 315
8.4.1 动态类型语言 316
8.4.2 Java与动态类型 317
8.4.3 java.lang.invoke包 318
8.4.4 invokedynamic指令 321
8.4.5 实战:掌控方法分派规则 324
8.5 基于栈的字节码解释执行引擎 326
8.5.1 解释执行 327
8.5.2 基于栈的指令集与基于寄存器的指令集 328
8.5.3 基于栈的解释器执行过程 329
8.6 本章小结 334
第9章 类加载及执行子系统的案例与实战 335
9.1 概述 335
9.2 案例分析 335
9.2.1 Tomcat:正统的类加载器架构 335
9.2.2 OSGi:灵活的类加载器架构 338
9.2.3 字节码生成技术与动态代理的实现 341
9.2.4 Backport工具:Java的时光机器 345
9.3 实战:自己动手实现远程执行功能 348
9.3.1 目标 348
9.3.2 思路 349
9.3.3 实现 350
9.3.4 验证 355
9.4 本章小结 356
第四部分 程序编译与代码优化
第10章 前端编译与优化 358
10.1 概述 358
10.2 Javac编译器 359
10.2.1 Javac的源码与调试 359
10.2.2 解析与填充符号表 362
10.2.3 注解处理器 363
10.2.4 语义分析与字节码生成 364
10.3 Java语法糖的味道 367
10.3.1 泛型 367
10.3.2 自动装箱、拆箱与遍历循环 375
10.3.3 条件编译 377
10.4 实战:插入式注解处理器 378
10.4.1 实战目标 379
10.4.2 代码实现 379
10.4.3 运行与测试 385
10.4.4 其他应用案例 386
10.5 本章小结 386
第11章 后端编译与优化 388
11.1 概述 388
11.2 即时编译器 389
11.2.1 解释器与编译器 389
11.2.2 编译对象与触发条件 392
11.2.3 编译过程 397
11.2.4 实战:查看及分析即时编译结果 398
11.3 提前编译器 404
11.3.1 提前编译的优劣得失 405
11.3.2 实战:Jaotc的提前编译 408
11.4 编译器优化技术 411
11.4.1 优化技术概览 411
11.4.2 方法内联 415
11.4.3 逃逸分析 417
11.4.4 公共子表达式消除 420
11.4.5 数组边界检查消除 421
11.5 实战:深入理解Graal编译器 423
11.5.1 历史背景 423
11.5.2 构建编译调试环境 424
11.5.3 JVMCI编译器接口 426
11.5.4 代码中间表示 429
11.5.5 代码优化与生成 432
11.6 本章小结 436
第五部分 高效并发
第12章 Java内存模型与线程 438
12.1 概述 438
12.2 硬件的效率与一致性 439
12.3 Java内存模型 440
12.3.1 主内存与工作内存 441
12.3.2 内存间交互操作 442
12.3.3 对于volatile型变量的特殊规则 444
12.3.4 针对long和double型变量的特殊规则 450
12.3.5 原子性、可见性与有序性 450
12.3.6 先行发生原则 452
12.4 Java与线程 455
12.4.1 线程的实现 455
12.4.2 Java线程调度 458
12.4.3 状态转换 460
12.5 Java与协程 461
12.5.1 内核线程的局限 461
12.5.2 协程的复苏 462
12.5.3 Java的解决方案 464
12.6 本章小结 465
第13章 线程安全与锁优化 466
13.1 概述 466
13.2 线程安全 466
13.2.1 Java语言中的线程安全 467
13.2.2 线程安全的实现方法 471
13.3 锁优化 479
13.3.1 自旋锁与自适应自旋 479
13.3.2 锁消除 480
13.3.3 锁粗化 481
13.3.4 轻量级锁 481
13.3.5 偏向锁 483
13.4 本章小结 485
附录A 在Windows系统下编译OpenJDK 6 486
附录B 展望Java技术的未来(2013年版) 493
附录C 虚拟机字节码指令表 499
附录D 对象查询语言(OQL)简介 506
附录E JDK历史版本轨迹 512