
线程通信
JDK API
suspend / resume
调用 suspend 挂起目标线程,通过 resume 恢复线程。已被废弃!被弃用的主要原因是,容易写出死锁的代码。所以用 wait/notify 和 park/unpark 机制进行替代。
死锁示例 1:在同步代码中使用
1 | /** 死锁的suspend/resume。 suspend并不会像wait一样释放锁,故此容易写出死锁代码 */ |
死锁示例 2:suspend 在 resume 后执行
1 | /** 导致程序永久挂起的suspend/resume */ |
wait / notify
wait 和 notify 方法只能由同一对象锁的持有者线程调用,也就是写在同步代码块里面,否则会抛出 aaa 异常。
- wait 方法导致当前线程等待,加入该对象的等待集合中,并且释放当前持有的对象锁。
- notify/notifyAll 方法唤醒一个或所有正在等待这个对象锁的线程。
注意:虽然 wait 会自动解锁,但是对顺序还是有要求,如果在 notify 被调用之后,才开始调用 wait,线程会永远处于 WAITING 状态。
永久等待示例
1 | /** 会导致程序永久等待的wait/notify */ |
park / unpark
线程调用 park 则等待“许可”,调用 unpark 方法为指定线程提供“许可(permit)”。不要求 park 和 unpack 方法的调用顺序。
多次调用 unpack 后,再调用 park,线程会直接运行。但不会叠加,也就是说,连续多次调用 park 方法,第一次会拿到“许可”直接运行,后续调用会进入等待。“许可”类似于标志位。
死锁示例
1 | /** 死锁的park/unpark */ |
伪唤醒
警告!之前代码中使用 if 语句来判断是否进入等待状态是错误的!
官方建议应该在循环中检查等待条件,原因是处于等待状态的线程可能会收到错误警报和伪唤醒,如果不在循环中检查等待条件,程序就会在没有满足结束条件的情况下退出。
伪唤醒是指线程并非因为 notify、notifyAll、unpark 等 API 调用而唤醒,而是因为更底层原因导致的。
总结
| 同步代码 | 代码顺序 | |
|---|---|---|
| suspend/resume | 死锁 | 永久挂起 |
| wait/notify | 无 | 永久等待 |
| park/unpack | 死锁 | 无 |
使用 while 循环代替 if 条件判断是否进入等待状态来避免伪唤醒。
线程封闭
通过将数据封闭在线程中而避免使用同步的技术称为线程封闭。
Java 中具体体现为 ThreadLocal、局部变量等。
ThreadLocal
ThreadLocal 是 Java 里一种特殊的变量。
ThreadLocal 是线程级别变量,每个线程都有自己独立的一个变量,竞争条件被彻底消除了,在并发模式下是绝对安全的变量。
可以理解为,JVM 维护了一个 Map<Thread, T>,每个线程要用这个 T 的时候,用当前的线程去 Map 里面取。
线程封闭示例
1 | /** 线程封闭示例 */ |
栈封闭
局部变量的固有属性之一就是封闭在线程中。
线程池
线程是不是越多越好?为什么要用线程池?
- 线程在 Java 中是一个对象,需要占用内存,更需要占用操作系统的资源,线程的创建、销毁都需要时间。如果创建时间 + 销毁时间 > 执行任务时间,就很不划算。
- Java 对象占用堆内存,操作系统线程占用系统内存,根据 JVM 规范,一个线程默认最大栈大小为 1M,这个栈空间是需要从系统内存中分配的。线程过多,会消耗大量的内存。
- 线程过多时,操作系统需要频繁切换线程上下文,影响性能。
线程池的推出,就是为了方便的控制线程数量。
概念
- 线程池管理器:用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务;
- 工作线程:线程池中的线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口:每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列:用于存放没有处理的任务,提供一种缓冲机制。
API
接口定义和实现类
| 类型 | 名称 | 描述 |
|---|---|---|
| 接口 | Executor | 最上层的接口,定义了执行任务的方法 execute |
| 接口 | ExecutorService | 继承了 Executor 接口,拓展了 Callable、Future、关闭方法 |
| 接口 | ScheduledExecutorService | 继承了 ExecutorService,增加了定时任务相关的方法 |
| 实现类 | ThreadPoolExecutor | 基础、标准的线程池实现 |
| 实现类 | ShceduledThreadPoolExecutor | 继承了 ThreadPoolExecutor,实现了 ScheduledExecutorService 中定时任务相关的方法 |
ExecutorService
1 | public interface ExecutorService extends Executor { |
ScheduledExecutorService
创建并执行一个一次性任务,过了延迟时间就会被执行
1 | public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit); |
创建并执行一个周期性任务,过了给定的初始延迟时间,会第一次被执行,执行过程中发生了异常,那么任务就停止。
一次任务执行时长超过了周期时间,下一次任务会等到该次任务执行结束后立即执行,这也是它和 scheduleWithFixedDelay 的重要区别。
1 | public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); |
创建并执行一个周期性任务,过了给定的初始延迟时间,第一次被执行后,后续以给定的周期时间执行,执行过程中发生了异常,那么任务就停止。
一次任务执行时长超过了周期时间,下一次任务会等到该次任务执行结束的时间基础上,计算执行延时。
Executors 工具类
public static ExecutorService newFixedThreadPool(int nThreads)创建一个固定大小、任务队列容量无界的线程池。核心线程数=最大线程数。
public static ExecutorService newCachedThreadPool()创建一个大小无界的缓冲线程池。它的任务队列是一个同步队列。任务加入到池中,如果池中有空闲线程,则用空闲线程执行,如无则创建新线程执行。池中的线程空闲超过 60 秒,将被销毁释放。线程数随任务的多少变化。适用于执行耗时较小的异步任务。池的核心线程数=0,最大线程数=Integer.MAX_VALUE
public static ScheduledExecutorService newSingleThreadScheduledExecutor()只有一个线程来执行无界任务队列的单一线程池。该线程池确保任务按加入的顺序一个一个一次执行。当唯一的线程因任务异常中止时,将创建一个新的线程来继续执行后续的任务。与
newFixedThreadPool(1)的区别在于,单一线程池的池大小在newSingleThreadExecutor方法中硬编码,不能再改变。public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)能定时执行任务的线程池。该池的核心线程数由参数指定,最大线程数=Interger.MAX_VALUE
任务执行过程
ThreadPoolExecutor.execute()
1 | public void execute(Runnable command) { |
graph TD
A[执行] --> B{是否达到核心线程数}
B --> |否|D[创建新线程执行]
B --> |是|C{工作队列是否已满}
C --> |否|E[丢到队列里]
C --> |是|F{是否达到最大线程数量}
F --> |否|G[新建线程执行]
F --> |是|H[执行拒绝策略]
线程数量
如何确定合适数量的线程?
- 计算型任务:CPU 数量的 1-2 倍
- IO型任务:相对计算型任务,需要多一些线程,要根据具体的 IO 阻塞时长进行考量决定。如 tomcat 中默认的最大线程数为 200。
- 也可以考虑根据需要在一个最小数量和最大数量间自动增减线程数。
CAS 机制
CAS(Compare and swap 比较和交换)属于硬件同步原语,处理器提供了基本内存操作的原子性保证。
CAS 操作需要输入两个数值,一个旧值A和一个新值B,在操作期间先比较旧值有没有发生变化,如果没有发生变化,才交换新值,否则不交换。
Java 中的 sun.misc.Unsafe 类,提供了 compareAndSwapInt() 和 compareAndSwapIong() 等几个方法实现 CAS。
1 | package com.gzhennaxia.demo; |
J.U.C 包内的原子操作封装类
- AtomicBoolean:原子更新布尔类型
- AtomicInteger:原子更新整型
- AtomicLong:原子更新长整型
- AtomicIntegerArray:原子更新整型数组里的元素
- AtomicLongArray:原子更新长整形数组里的元素
- AtomicReferenceArray:原子更新引用类型数组里的元素
- AtomicIntegerFieldUpdater:原子更新整型字段的更新器
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
- AtomicReferenceFieldUpdater:原子更新饮用类型的字段
- AtomicReference:原子更新引用类型
- AtomicStampedReference:原子更新带有版本号的引用类型
- AtomicMarkableReference:原子更新带有标记位的引用类型
1.8 更新:
更新器:DoubleAccumulator、LongAccumulator
计数器:DoubleAdder、LongAdder
计数器增强版,高并发下性能更好
频繁更新但不太频繁读取的汇总统计信息时使用
分成多个操作单元,不同线程更新不同的单元
只有需要汇总的时候才计算所有单元的操作
CAS 的三个问题
循环+CAS,自旋的实现让所有线程都处于高频运行,争抢 CPU 执行时间的状态。如果操作长时间不成功,会带来很大的 CPU 资源消耗。
仅针对单个变量的操作,不能用于多个变量来实现原子操作。
-
线程1将A修改为B,线程2将B修改为C,线程3将B修改为A。
如果执行顺序为线程1 -> 线程3 -> 线程2,则线程2将无法感知到线程1和线程3的修改。
Java 锁
自旋锁:为了不放弃 CPU 执行事件,循环的使用 CAS 技术对数据进行更新,直至成功。
悲观锁:假定会发生并发冲突,同步所有对数据的相关操作,从读数据就开始上锁。
乐观锁:假定没有冲突,在修改数据时如果发现和之前获取的不一样,则读最新数据,修改后重试修改。
自旋锁就是乐观锁的一种体现。
独享锁(写):给资源加上写锁,线程可以修改资源,其他线程不能再加锁;(单写)
共享锁(读):给资源加上读锁后只能读不能改,其他线程也只能加读锁,不能加写锁;(多读)
可重入锁、不可重入锁:线程拿到一把锁之后,可以自由进入同一把锁所同步的其他代码。
公平锁、非公平锁:争抢锁的顺序,如果是按先来后到,则为公平。
几种重要的锁实现:synchronized、ReentrantLock、ReentrantReadWriteLock
同步关键字 synchronized
synchronized 属于最基本的线程通信机制,基于对象监视器实现。
Java 中的每个对象都与一个监视器相关联,一个线程可以锁定或解锁。
一次只有一个线程可以锁定监视器,试图锁定该监视器的任何其他线程都会被阻塞,直到它们可以获得该监视器上的锁定为止。
特性:可重入、独享、悲观锁
锁的范围:类锁、对象锁、锁消除、锁粗化
提示:同步关键字,不仅是实现同步,根据 JMM 规定,还能保证可见性(读取最新主内存数据,结束后写入主内存)。
示例
可重入
1 | // 可重入 |
锁粗化
1 | // 锁粗化(运行时 jit 编译优化) |
锁消除
1 | // 锁消除(jit) |
synchronized 加锁原理
Java中的
synchronized有偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。当条件不满足时,锁会按偏向锁->轻量级锁->重量级锁的顺序升级。The Hotspot Java Virtual Machine
https://wiki.openjdk.java.net/display/hotspot/synchronization
Lock 锁接口实现
Lock 核心API
| API | 描述 |
|---|---|
| lock | 获取锁的方法,若锁被其他线程获取,则等待(阻塞) |
| lockInterruptibly | 在锁的获取过程中可以中断当前线程 |
| tryLock | 尝试非阻塞地获取锁,立即返回 |
| unlock | 释放锁 |
提示:根据Lock接口的源码注释,Lock接口的实现,具备和同步关键字同样的内存语义。
ReentrantLock
- 独享锁
- 支持公平、非公平两种模式
- 可重入
1 | // 可响应中断 |
ReadWriteLock
维护一对关联锁,一个用于只读操作,一个用于写入;读锁可以由多个读线程同时持有,写锁是排他的。
适合读取线程比写入线程多的场景,改进互斥锁的性能,示例场景:缓存组件、集合的并发线程安全性改造。
锁降级指的是写锁降级为读锁。把持住当前拥有的写锁的同时,再获取到读锁,随后释放写锁的过程。
写锁是线程独占,读锁是共享,所以写->读是降级。(无法实现读->写)
Codition
用于替代 wait/notify
Object 中的 wait(),notify(),notifyAll() 方法是和 synchronized 配合使用的,可以唤醒一个或者全部(单个等待集);
Condition 是需要与 Lock 配合使用的,提供了多个等待集合,更精确的控制(底层是 park/unpark 机制);
1 | // condition 实现队列线程安全。 |
AQS 抽象队列同步器
运用到模版方法设计模式
即算法的整体骨架已确定,某些具体的步骤由子类去实现。
提供了对资源占用、释放,线程的等待、唤醒等等接口和具体实现。
可以用在各种需要控制资源争用的场景中。(ReentrantLock/CountDownLatch/Semphore)
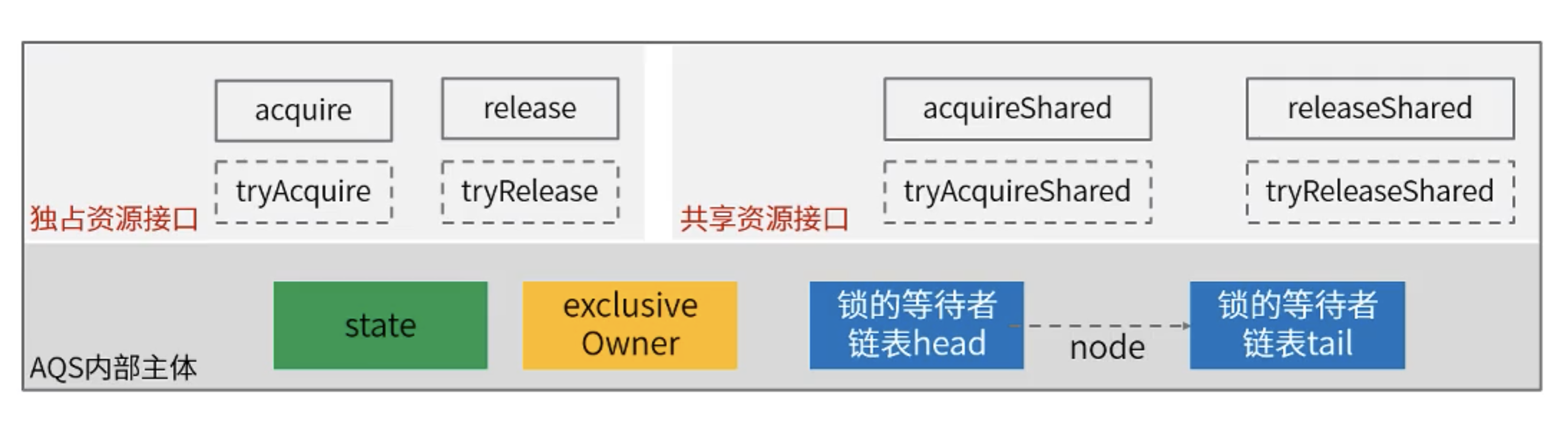
acquire、acquireShared:定义了资源争用的逻辑,如果没拿到,则等待。
tryAcquire、tryAcquireShared:实际执行占用资源的操作,如何判定由使用者具体去实现。
release、releaseShared:定义释放资源的逻辑,释放之后,通知后续节点进行争抢。
tryRelease、tryReleaseShared:实际执行资源释放的操作,具体的AQS使用者去实现。
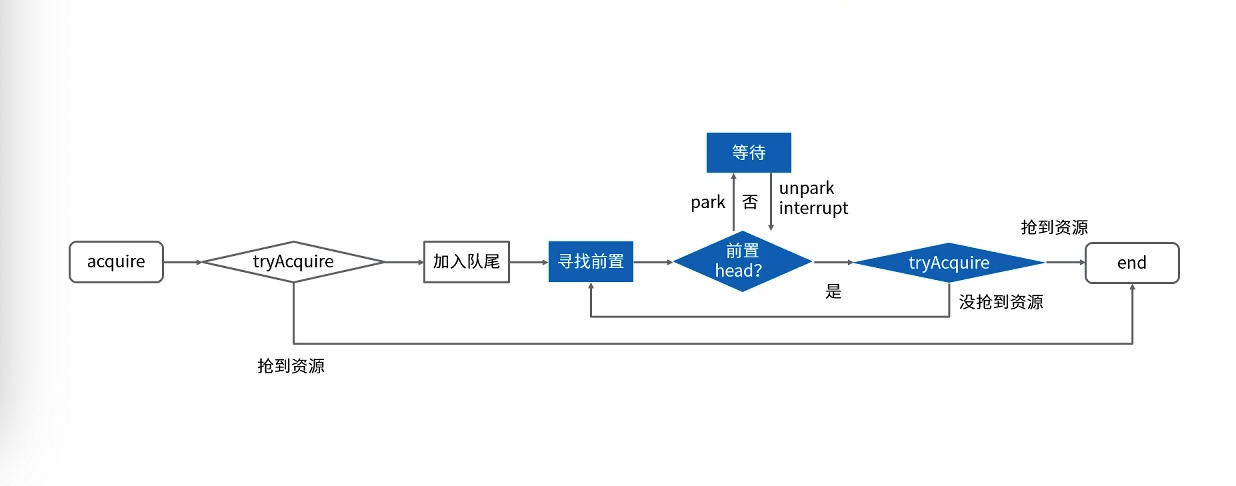
graph TD
A[acquire] --> B{tryAcquire}
B --> D[加入队尾]
B --> |抢到资源|C[end]
D --> E[寻找前置]
E --> F{前置节点是否为头节点}
F --> |是|G{tryAcquire}
F --> |否 park|H[等待]
H --> |unpark/interrupt|F
G --> |抢到资源|C
G --> |没抢到资源|E
信号量、栅栏和倒计时器
Semaphore
Semaphore 称为“信号量”,控制多个线程争抢许可。
- acquire:获取一个许可,如果没有就等待。
- release:释放一个许可。
- availablePermits:获取可用许可数目
典型场景:
- 代码并发处理限流(Hatrix);
CountDownLatch
Java1.5 被引入的一个工具类,常被称为“倒计数器”。
创建对象时,传入指定数值作为线程参与的数量;
await:该方法等待计数器变为0,在这之前,线程进入等待状态;
countdown:计数器数值减一,知道为0;
经常用于等待其他线程执行到某一节点,再继续执行当前线程代码。
使用场景示例:
- 统计线程执行的情况;
- 压力测试中,使用 countDownLatch 实现最大程度的并发处理;
- 多个线程之间,相互通信,比如线程异步调用接口,结果通知;
1 | public class CountDownLatchDemo { |
CyclicBarrier
CyclicBarrier 也是1.5引入的,又称为“线程栅栏”。
创建对象时,指定栅栏线程数量。
await:等指定数量多线程都处于等待状态时,继续执行后续代码。
barrierAction:线程数量到了指定量后,自动触发执行指定任务。
和 CountDownLatch 的重要区别在于,CyclicBarrier 对象可以多次触发执行。
典型场景:
- 数据量比较大时,实现批量插入数据到数据库;
- 数据统计,30个线程统计30天数据,全部统计完毕后,执行汇总;
J.U.C 并发容器类
Map
HashMap / ConcurrentHashMap 源码分析
探索 ConcurrentHashMap 高并发性的实现机制
ConcurrentSkipListMap

特点:
有序链表实现
无锁实现(使用CAS)
value 不能为空
层级越高,跳跃性越大,数据约少,速度越快
随机决定新节点是否抽出来作为索引
时间复杂度为 O(log n),空间复杂度为 O(n)
List
CopyOnWriteArrayList
CopyOnWriteArrayList 容器即写时复制容器,和 ArrayList 相比,优点是并发安全,缺点有两个:
- 多了内存占用:写数据是 copy 一份完整的数据,单独进行操作。
- 数据一致性:数据写完之后,其他线程不一定能马上读取到最新内容。
Set
| 实现 | 原理 | 特点 |
|---|---|---|
| HashSet | 基于 HashMap 实现 | 非线程安全 |
| CopyOnWriteArraySet | 基于 CopyOnWriteArrayList | 线程安全 |
| ConcurrentSkipListSet | 基于 ConcurrentSkipListMap | 线程安全,有序,查询快 |
Queue
| 方法 | 作用 | 描述 |
|---|---|---|
| add | 添加元素 | 如果队列已满,则抛出 IllegalStateException 异常 |
| remove | 移除并返回队列头部的元素 | 如果队列为空,则抛出 NoSuchElementException 异常 |
| element | 返回队列头部的元素 | 如果队列为空,则抛出 NoSuchElementException 异常 |
| offer | 添加一个元素并返回 true | 如果队列已满,则返回 false |
| poll | 移除并返回队列头部的元素 | 如果队列为空,则返回 null |
| peek | 返回队列头部的元素 | 如果队列为空,则返回 null |
| put | 添加一个元素 | 如果队列已满,则阻塞 |
| take | 移除并返回队列头部的元素 | 如果队列为空,则阻塞 |
fork/join 并发处理框架
Fork/Join 框架是 Java7 提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
ForkJoinPool 是 ExecutorService 接口的实现,专为可以递归分解的工作而设计。
分解任务的代码一般使用 RecursiveTask(带返回结果) 或者其子类 RecursiveAction。
适合数据处理、结果汇总、统计等场景;
Java 8 实例:java.util.Arrays#parallelSort() 方法。
工作窃取带来的性能提升偏理论,API 的复杂性较高,实际研发中可控性来说不如其他 API。
Future
Future 表示异步计算的结果,提供了用于检查计算是否完成、等待计算完成以及获取结果的方法。
网络
TCP/UDP 协议
传输控制协议 TCP
传输控制协议(TCP,Transmission Control Protocol)是一个传输层协议,提供面向连接的、可靠的、有序的、基于字节流的传输层通信协议。应用程序在使用 TCP 之前,必须先建立 TCP 连接。
TCP 三次握手
TCP 四次挥手
为什么需要四次挥手?
四次挥手是为了连接双方能够安全的释放资源(连接双方会存储对方的地址信息)。
少于四次无法实现这个目的,假如客户端率先发起断开连接的请求:
第一次挥手:客户端发送断开连接的请求给服务器
此时服务器由于还需要发报文给客户端,因此无法释放资源(即删除客户端地址信息);而客户端还没有收到服务器的确认报文,需要持续监听,因此也无法释放资源(即删除服务器地址信息)。
第二次挥手:服务器发送确认报文给客户端
此时服务器由于还需要发送数据报文给客户端,因此无法自身释放资源;而客户端还需要继续监听服务端,也无法释放自身资源。
第三次挥手:服务器发送断开连接的请求给客户端
此时服务器由于还没收到客户端的确认报文,需要继续监听,所以无法释放资源;而客户端需要发送确认报文,也无法释放资源。
第四次挥手:客户端发送确认报文给服务器
当服务器收到该报文后就可以释放资源了,但客户端由于无法确定该报文是否被收到了,所以还无法释放资源,需要等待 2MSL 时间后才能释放资源。
四次挥手是为了连接双方能够断开彼此之间的数据通道。少于四次无法实现这个目的。
假如客户端率先发起断开连接的请求:
第一次挥手:客户端发送断开连接的请求给服务器
为了实现安全性,需要等待服务器的确认报文。
第二次挥手:服务器发送确认报文给客户端
由于 TCP 是全双工模式,双通道相互独立,故服务器还可以继续发送数据报文给客户端,此时客户端往服务器端的数据通道关闭,TCP 连接处于半关闭状态。
第三次挥手:服务器发送断开连接的请求给客户端
为了安全性,需要等待客户端的确认报文。
第四次挥手:客户端发送确认报文给服务器
当服务器接收到该报文后即可关闭连接,但客户端在发送完该报文后并不能确保服务器是否已收到,需要等待 2MSL 时间后再关闭。
2MSL等待状态
报文段最大生存时间MSL(Maximum Segment Lifetime),在第四次挥手后主动端之所以还需要等待 2MSL 时间,是因为它无法保证报文是否被接收到,但如果假设报文丢失了,那么被动端会在 2MSL 时间内再发送一次断开连接的请求,此时主动端就可以判定确认报文丢失了,然后重新发送一次确认报文,如果 2MSL 时间内没有收到被动端再一次的断开连接请求,就认为被动端已经收到确认报文了,就可以关闭连接了。
用户数据报协议 UDP
用户数据报协议属于传输层协议。提供无连接、不可靠、数据报尽力传输服务。
Socket 编程
应用最广泛的网络应用编程接口
- 数据报类型套接字 SOCK_DGRAM(面向 UDP 接口)
- 流式套接字 SOCK_STREAM(面向 TCP 接口)
- 原始套接字 SOCK_RAW(面向网络层协议接口 IP、ICMP等)
Socket API 调用过程
graph TD
A[创建套接字] --> B[端点绑定]
B --> C[发送数据]
C --> D[接收数据]
D --> F[释放套接字]
Socket API 函数
listen()、accept() 函数只能用于服务器端;
connect() 函数只能用于客户端;
socket()、bind()、send()、recv()、sendto()、recvfrom()、close()
BIO
阻塞 IO 的含义
阻塞(blocking)IO:资源不可用时,IO 请求一直阻塞,直到反馈结果(有数据或超时)。
非阻塞(non-blocking)IO:资源不可用时,IO 请求立即返回,返回数据标识资源不可用。
同步(synchronous)IO:应用阻塞在发送或接收数据的状态,直到数据成功传输或返回失败。
异步(asynchronous)IO:应用发送或接收数据后立刻返回,实际处理是异步执行的。
阻塞和非阻塞是获取资源的方式,同步/异步是程序如何处理资源的逻辑设计。
我的理解:阻塞/非阻塞是指单个线程的状态,同步/异步是指多个线程之间的关系。
API:ServerSocket#accept、InputStream#read 都是阻塞的API。操作系统底层 API 中,默认 Socket 操作都是 Blocking 型,send/recv 等接口都是阻塞的。
BIO 带来的问题:阻塞导致在处理网络 IO 时,一个线程只能处理一个网络连接。
NIO
NIO 始于 Java 1.4。
NIO 有三个核心组件:
- Buffer 缓冲区
- Channel 通道
- Selector 选择器
Buffer
使用 Buffer 进行数据读写,需要如下四个步骤:
- 将数据写入缓冲区
- 调用 buffer.flip() 转换为读取模式
- 缓冲区读取数据
- 调用 buffer.clear() 或 buffer.compact() 清除缓冲区
Buffer 原理
三个重要属性:
- capacity
- position:写入模式时代表写数据的位置,读取模式时代表读取数据的位置。
- limit:写入模式时等于 capacity,读取模式时代表写入的数据量。
ByteBuffer
ByteBuffer 为性能关键型代码提供了直接内存(direct 堆外)和非直接内存(heap 堆)两种实现。
堆外内存获取的方式:ByteBuffer.allocateDirect(noBytes);
好处:
- 进行网络 IO 或者文件 IO 时比 heapBuffer 少一次拷贝(file/socket — OS memory — jvm heap)。GC 会移动对象内存,在写 file 或 socket 的过程中,JVM 的实现中,会先把数据复制到堆外,再进行写入。
- GC 范围之外,降低 GC 压力,但实现了自动管理。DirectByteBuffer 中有一个 Cleaner 对象(PhantomReference),Cleaner 被 GC 前会执行 clean 方法,触发 DirectByteBuffer 中定义的 Deallocator
建议:
- 性能确实可观的时候才去使用;分配给大型、长寿命;(网络传输、文件读写场景)
- 通过虚拟机参数 MaxDirectMemorySize 限制大小,防止耗尽整个机器的内存;
Channel
SocketChannel
SocketChannel 用于建立 TCP 网络连接,类似 java.net.Socket。有两种创建 SocketChannel 的形式:
- 客户端主动发起和服务器的连接
- 服务端获取的新连接
write:write() 在尚未写入任何内容时就可能返回了。需要在循环中调用 write()。
read:read() 方法可能直接返回而不读取任何数据,根据返回的 int 值判断读了多少字节。
ServerSocketChannel
ServerSocketChannel 可以监听新建的 TCP 连接通道,类似 ServerSocket。
ServerSocketChannel.accept():如果该通道出去非阻塞模式,那么如果没有挂起的连接,该方法将立即返回 null。必须检查返回的 SocketChannel 是否为 null。
Selector
Selector 实现一个线程处理多个通道:事件驱动机制。
非阻塞的网络通道下,开发者通过 Selector 注册对于通道感兴趣的事件类型,线程通过监听事件来触发相应的代码执行。(拓展:更底层是操作系统的多路复用机制)
NIO VS BIO
BIO,阻塞 IO,线程等待时间长,一个线程负责一个连接处理,线程多且利用率低。
NIO,非阻塞 IO,线程利用率更高,一个线程处理多个连接事件,性能更强大。
Tomcat 8 中,已经完全去除 BIO 相关的网络处理代码,默认采用 NIO 进行网络处理。
NIO 与多线程结合的改进方案
小结
NIO 为开发者提供了功能丰富及强大的 IO 处理 API,但是在应用与网络应用开发的过程中,直接使用 JDK 提供的 API,比较繁琐。而且要想将性能进行提升,光有 NIO 还不够,还需要将多线程技术与之结合起来。
因为网络编程本身的复杂性,以及 JDK API 开发的使用难度较高,所以在开源社区中,涌现出很多对 JDK NIO 进行封装、增强后对网络编程框架,例如:Netty、Mina 等。
Netty
Netty 是一个高性能、高可扩展性的异步事件驱动的网络应用程序框架,它极大地简化了 TCP 和 UDP 客户端和服务器开发等网络编程。
Netty 重要的四个内容:
- Reactor 线程模型:一种高性能的多线程程序设计思路
- Netty 中自己定义的 Channel 概念:增强版的通道概念
- ChannelPipeline 职责链设计模式:事件处理机制
- 内存管理:增强的 ByteBuf 缓冲区
Netty 线程模型
为了让 NIO 处理更好的利用多线程特性,Netty 实现了 Reactor 线程模型。
Reactor 模型中有四个核心概念:
- Resources 资源(请求/任务)
- Synchronous Event Demultiplexer 同步事件复用器
- Dispatcher 分配器
- Request Handler 请求处理器
Channel 概念
Netty 中的 Channel 是一个抽象的概念,可以理解为对 JDK NIO Channel 的增强和拓展。增加了很多属性和方法。
责任链设计模式
模式结构
责任链模式包含如下角色:
- 处理器抽象类
- 具体处理器
- 处理器链维护器(可选):维护了各个处理器的前后关系。可以由客户端再发送请求前生成链,或者动态地生成链。
- 客户端
伪例
请假流程
请假请求类:LeaveRequest
1 | public class LeaveRequest { |
处理器抽象类:LeaveRequestHandler
1 | public abstract class LeaveRequestHandler { |
处理器具体类:SupervisorHandler、ManagerHandler、GeneralManagerHandler
1 | public class SupervisorHandler extends LeaveRequestHandler { |
客户端:Worker
1 | public class Worker { |
零拷贝机制
类加载机制
一个 Java 程序运行,至少有三个类加载器实例,负责不同类的加载。
Bootstrap loader 核心类库加载器
C/C++实现,无对应 Java 类:null
加载 JRE_HOME/jre/lib 目录,或用户配置的目录,JDK 核心类库 r t.jar…
Extension Class Loader 扩展类库加载器
ExtClassLoader 的实例:
加载 JRE_HOME/jre/lib/ext 目录,JDK 扩展包,或用户配置的目录
Application Class Loader 用户应用程序加载器
AppClassLoader 的实例:
加载 java.class.path 指定的目录,用户应用程序 class-path,或者 Java 命令运行时参数 -cp…
查看类对应加载器的方法:java.lang.Class.getClassLoader()
该方法返回装载类的类加载器,如果这个类是由 BootstrapClassLoader 加载的,那么返回 null。
不会重复加载
双亲委派模型
垃圾回收机制
标记算法
- 引用计数
- 可达性分析算法
引用类型
可达性级别
收集算法
JVM 命令工具
javap
jps
jstat
jcmd
jinfo
jhat
jmap
jstack
jconsole
JvisualVM
JVM 调优
Tomcat
Tomcat 网络处理线程模型
BIO + 同步 Servlet
Tomcat 7 及以前使用 BIO + 同步 Servlet,一个请求使用一个线程。
APR + 异步 Servlet
Apache可移植运行时(Apache Portable Runtime,简称APR)是Apache HTTP服务器的支持库,提供了一组映射到下层操作系统的API。
JNI 的形式调用 Apache HTTP 服务器的核心动态链接库来处理文件读取或网络传输操作。
Tomcat 默认监听指定路径,如果有 APR 安装,则自动启动。
NIO + 异步 Servlet
Tomcat 8 开始默认使用 NIO
Tomcat 参数调优
中间件
消息中间件
AMQP 协议
高级消息队列协议即Advanced Message Queuing Protocol是面向消息中间件提供的开放的应用层协议,其设计目标是对于消息的排序、路由、保持可靠性、保证安全性。 维基百科
MQTT 协议
MQTT消息队列遥测传输(Message Queuing Telemetry Transport)是ISO 标准下基于发布 /订阅 范式的消息协议,可视为“资料传递的桥梁”它工作在TCP/IP协议族上,是为硬件性能低下的远程设备以及网络状况糟糕的情况下而设计的发布/订阅型消息协议,为此,它需要一个消息中间件,以解决当前繁重的资料传输协议,如:HTTP。 维基百科
OpenMessaging 协议
Kafka 协议
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。 维基百科
Kafka 协议是居于 TCP 的二机制协议。消息内部是通过长度来分割,由一些基本数据类型组成。
消息持久化
| ActiveMQ | RabbitMQ | Kafka | RocketMQ | |
|---|---|---|---|---|
| 文件系统 | 支持 | 支持 | 支持 | 支持 |
| 数据库 | 支持 | / | / | / |
消息分发策略
| ActiveMQ | RabbitMQ | Kafka | RocketMQ | |
|---|---|---|---|---|
| 文件系统 | 支持 | 支持 | 支持 | 支持 |
| 轮询分发 | 支持 | 支持 | 支持 | / |
| 公平分发 | / | 支持 | 支持 | / |
| 重发 | 支持 | 支持 | / | 支持 |
| 消息拉取 | / | 支持 | 支持 | 支持 |
集群
Master-Slave 主从共享部署方式
Master-Slave 主从同步部署方式
Broker-Cluster 多主集群同步部署方式
Broker-Cluster 多主集群转发部署方式
ActiveMQ
Apache ActiveMQ是Apache软件基金会所研发的开放源码消息中间件;由于ActiveMQ是一个纯Java程序,因此只需要操作系统支持Java虚拟机,ActiveMQ便可执行。 维基百科
JMS 规范
Java消息服务应用程序接口是一个Java平台中关于面向消息中间件的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的API,绝大多数MOM提供商都对JMS提供支持。 Java消息服务的规范包括两种消息模式,点对点和发布者/订阅者。 维基百科
JMS 对象模型
JMS 消息模型
点对点
发布订阅
JMS 消息结构
- 消息头
- 消息属性
- 消息体类型
ActiveMQ 高可用集群方案
ActiveMQ 持久化
JDBC 方式
性能低
AMQ 方式
KahaDB 方式
LevelDB 方式
已被摒弃
事务机制
Nginx
Nginx 不执行动态语言,只能作为静态资源服务器。
负载均衡
- 轮询
- 最少连接
- IP hash
- 基于权重
代理缓存
通过 Lua 拓展 Nginx
Lua 使得 Nginx 可以支持动态语言。
协程(Coroutine)
Nginx 进程模型
OpenResty
OpenResty是基于nginx的Web平台,可以使用其LuaJIT引擎运行Lua脚本。该软件是由Yichun Zhang创建的。它最初是在2011年前由Taobao.com赞助的,在2012年至2016年期间主要由Cloudflare支持。 维基百科(英文)
高性能 Nginx 最佳实践
监听端口
虚拟主机
配置 location
常规配置
定义环境变量
嵌入其他配置文件
pid文件
worker 进程运行的用户和用户组
指定 worker 进程可以打开的最大句柄描述符个数
限制信号队列
高性能配置
worker 进程个数
绑定 worker 进程到指定 CPU 内核
SSL 硬件加速
worker 进程优先级设置
事件配置
是否打开 accept 锁
使用 accept 锁后到真正建立连接之间的延迟时间
批量建立新连接
选择事件模型
每个 worker 的最大连接数
Nginx 事件模型
epoll
LVS 负载均衡软件
Linux虚拟服务器(Linux Virtual Server)是一个虚拟的服务器集群系统,用于实现负载平衡。项目在1998年5月由章文嵩成立,是中国国内最早出现的自由软件项目之一。 维基百科
IP 虚拟服务器软件 IPVS
Virtual Server via Direct Routing (VS/DR)
Virtual Server via Network Address Translation (VS/NAT)
Virtual Server via IP Tunneling (VS/TUN)
IPVS 调度算法
八种负载调度算法
内核 Layer-7 交换机 KTCPVS
LVS 与 Nginx 对比
基于 VIP 的 keepalived 高可用架构
Keepalived
工作原理
应用场景
高可用集群
高可用架构
使用 CDN 实现应用的缓存和加速
CDN
服务模式
工作流程
关键技术
缓存
谷歌 Guava 缓存
Guava Cache 是 Google Guava 中的一个内存缓存模块,用于将数据缓存到 JVM 内存中。
Spring Cache
Redis
常用命令
数据结构
GEO
Stream
持久化
RDB
AOF
内存管理
内存分配
- String 类型的 value 最大可存储 512M。
- List 类型,元素个数最多 2^32-1
- Set 类型,元素个数最多 2^32-1
- Hash 类型,键值对个数最多 2^32-1